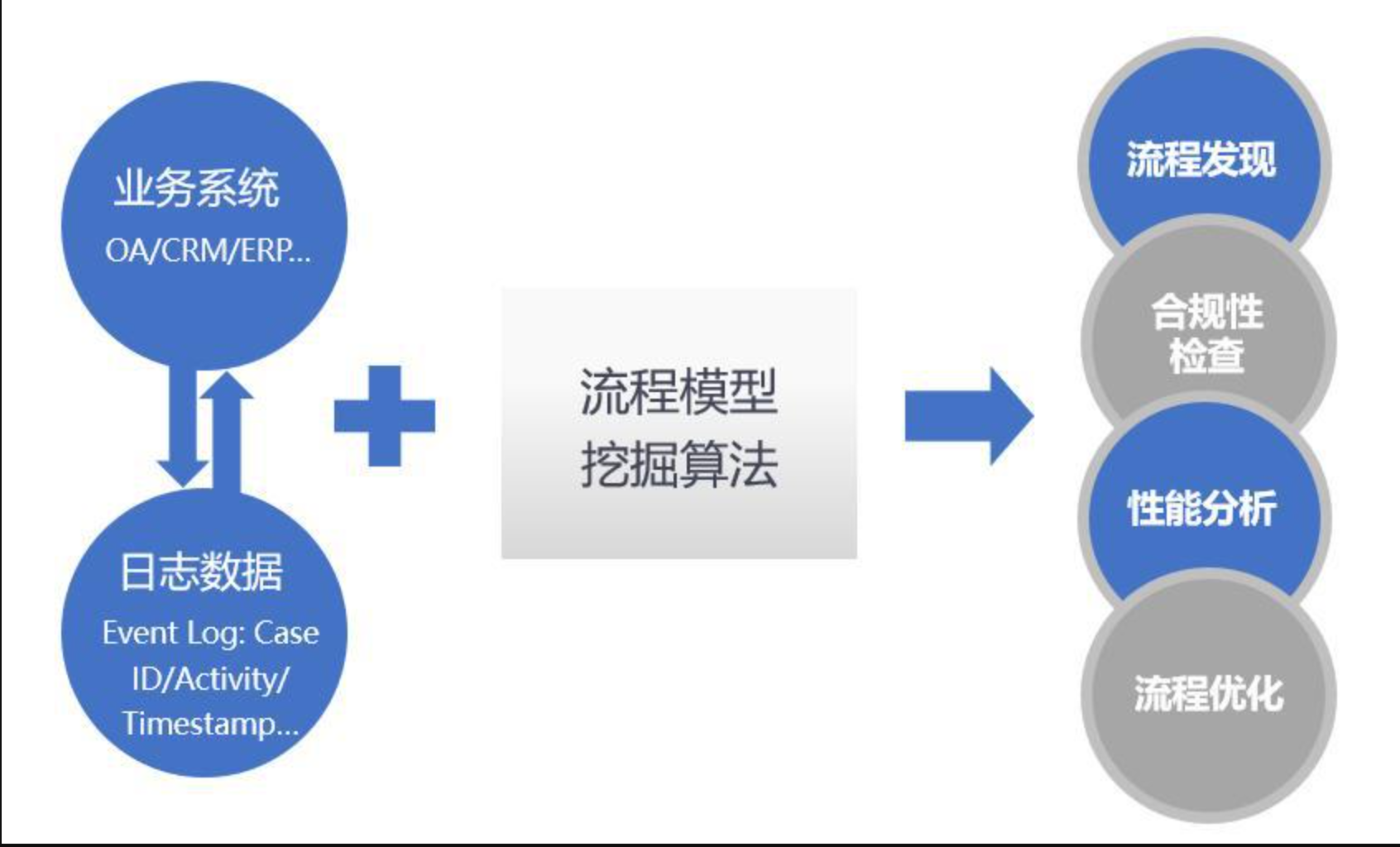
『科研』流程挖掘领域研究现状总结
上一篇文章对流程挖掘领域的关键技术进行了总结,这篇文章主要对流程挖掘领域的研究现状进行了总结。
研究团队
关键词
- 流程挖掘 Process Mining
- 流程发现 Process Discovery
- 业务树 process tree
- 事件日志 event log
- 流程挖掘异常检测:知网搜索可以搜到很多毕业安徽理工大学的论文
- 业务流程管理
- 流程变体分析:企业或组织的业务流程因涉及不同的地域、人员或法规等而存在很多变体,不同流程变体的事件日志中存在差异。流程变体分析是流程挖掘的一个范畴,能够从事件日志中发现两个流程变体的差异,对流程变体进行比较分析,从而为流程标准化、流程改进和拓展等提供帮助。
- “Topic=‘process mining’” and “Topic=‘Algorithm’”
数据集
大多数流程挖掘领域的文章都是在BPIC数据集的基础上进行研究
BPIC 是 “Business Process Intelligence Challenge” 的缩写,是一个由荷兰埃因霍温理工大学(Eindhoven University of Technology)发起的年度学术竞赛。BPIC 数据集 是该比赛中发布的一系列真实业务流程事件日志数据,用于研究和测试流程挖掘(Process Mining)技术。
流程发现
流程挖掘具有三个不同的视角:
- 过程视角(process perspective):关注控制流,即活动的优先关系
- 组织视角(organizational perspective):关注参加的角色及其之间的关系
- 案例视角(case perspective):关注case的属性
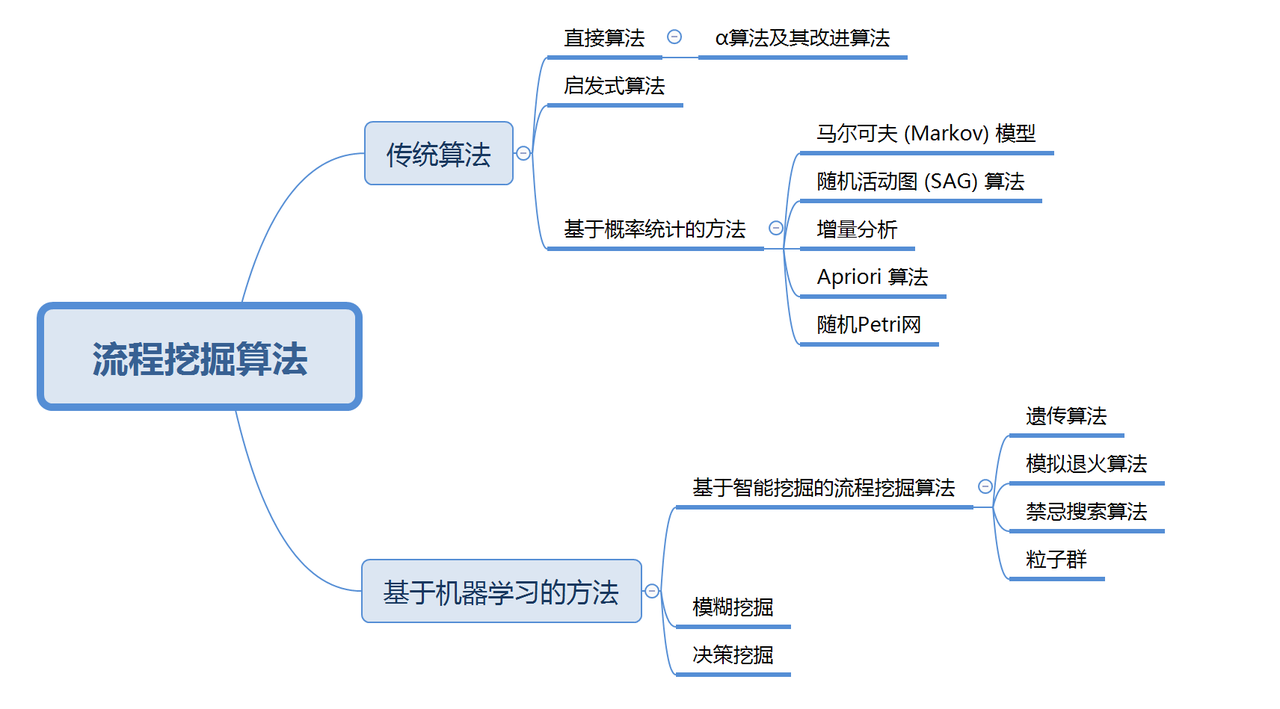
流程挖掘算法综述
- 2022
- 流程挖掘算法综述_林文祥.pdf
对流程挖掘算法进行了总结
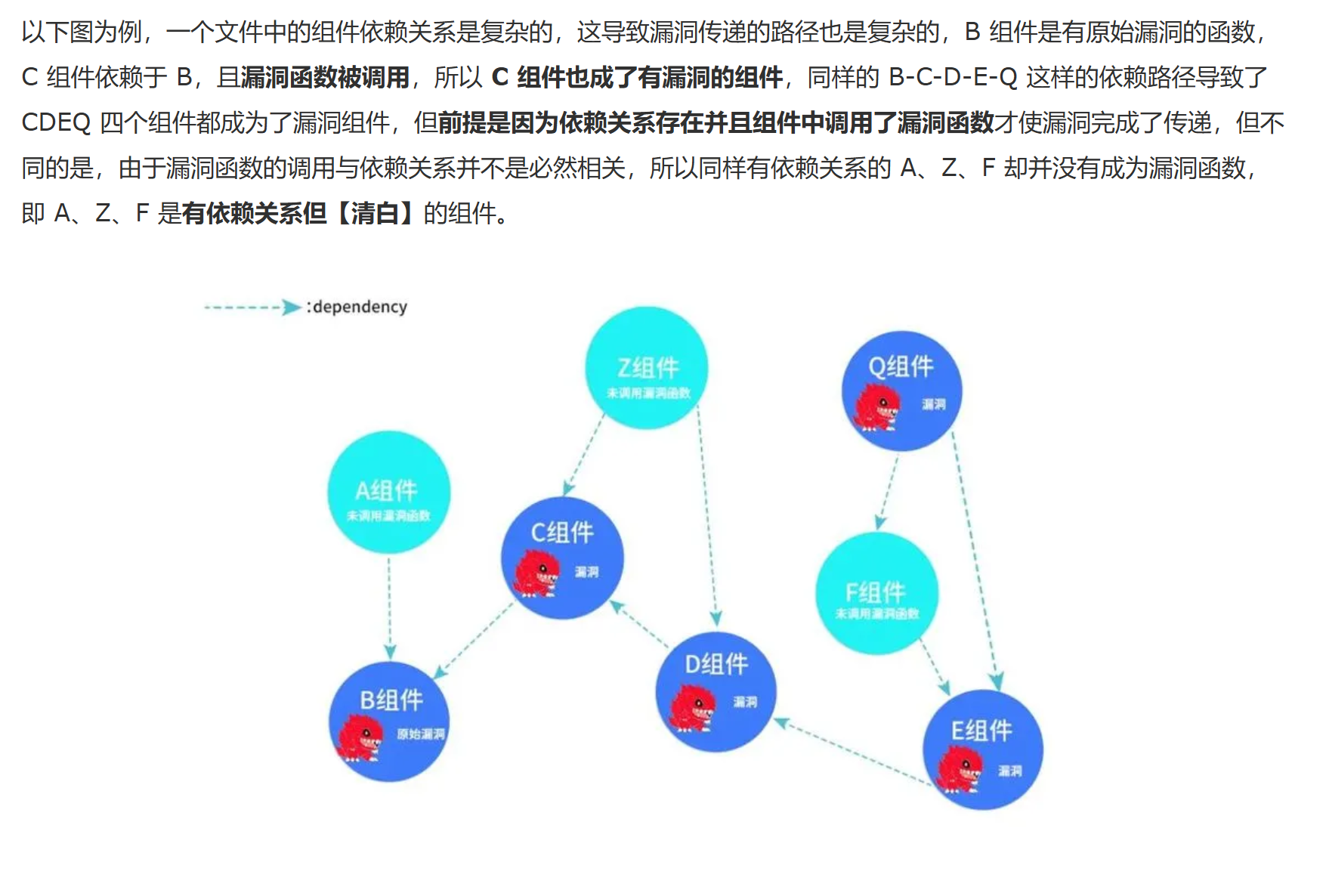
Algorithms for anomaly detection of traces in logs of process aware information systems
- Information Systems 中科院二区
- 2013
- https://repositorio.ufra.edu.br/jspui/bitstream/123456789/371/1/ALGORITHMS FOR ANOMALY DETECTION OF TRACES IN LOGS....o.pdf
真实应用场景下的日志中通常包含异常执行信息,因此通过流程发现技术挖掘得到的模型并不完全标准。
针对这一问题提出了三种改进的异常检测方法:
- 阈值算法:设置一个异常阈值,将一致性低于阈值的轨迹归为异常轨迹来实现异常检测;
- 迭代算法:通过多次迭代并在每次迭代中删除一致性最低的轨迹来达到过滤异常的效果;
- 采样算法:通过采样来减少日志中包含异常轨迹的可能性,基于假设:日志中所包含的异常数据是少量的
Process variant comparison: Using event logs to detect differences in behavior and business rules
- Information Systems CCF-B
- 2018
- https://www.sciencedirect.com/science/article/pii/S0306437916305257
背景:同一个公司的同一个流程在不同部门、客户群体或时间段之间可能存在差异,如同一个银行在不同地区、时间的借贷额度可能不同,这些可以表示为同一个流程的不同变体。这些流程变体受到多种因素的影响,如年度时间、执行的地理位置或负责的资源单元等。导致企业需要深入了解比较不同流程的执行方式,进行流程优化。
现有方法的不足:现有的一些对比流程变体的方法主要关注“控制流”这一角度,但这些方法通常只能检测到统计上不显著的差异,无法识别真正有意义的行为差异。同时现有方法无法基于业务规则或性能指标的注释来有效检测流程变体之间的统计显著差异。
研究内容:作者提出了一种基于transition systems的流程变体对比方法。该方法可以从事件日志中提取信息,检测不同流程变体之间在各类测量注释(如控制流频率、时间等方面)上的统计显著差异。通过使用转移系统,可以避免依赖特定的数据挖掘算法,并且该系统可以从多种角度创建(如不仅考虑控制流,还可以考虑资源交互等)。用户还可以通过不同的参数控制结果,使其更具灵活性。
Discovering Process Models that Support Desired Behavior and Avoid Undesired Behavior
Process mining using BPMN: relating event logs and process models
- MODELS '16 CCF-B
- 2016
- https://pure.tue.nl/ws/portalfiles/portal/4007431/1379614664264.pdf
提供了一种根据 BPMN 发现流程的控制流视角的方法
Evaluating and Predicting Overall Process Risk Using Event Logs
- Information Sciences CCF-B 中科院一区
- 2016
Split miner: automated discovery of accurate and simple business process models from event logs
- Knowledge and Information Systems CCF-B 高引用
- 2019
Fuzzy Mining Adaptive Process Simplification Based on Multi-Perspective Metrics
待看:
-
Workflow mining: Discovering process models from event logs CCF A
-
Discovering expressive process models by clustering log traces CCF A
-
OrgMiner: A Framework for Discovering User-Related Process Intelligence from Event Logs 2020
-
Hidden markov model for process mining of parallel business processes
轨迹聚类
为什么要使用轨迹聚类
在灵活性较高的流程中,流程的实际执行情况可能会因不同情况而有所偏离,为非结构化,从而导致所有可能的行为都显示在单个流程模型中**,复杂且难以解读**。在这些领域,生成的流程模型往往存在大量分支和变异(即意大利面条式流程模型),使得模型的直观性和可解释性较差。
这时候可以使用轨迹聚类的方式来进行预处理,找出日志中不同聚类簇,每个簇单独展示了一个特定的过程模型(即完整模型中的部分行为),通过刻画局部行为来降低模型的复杂度,使得后续生成的流程模型更加简单,可读性高。
轨迹聚类和概念漂移
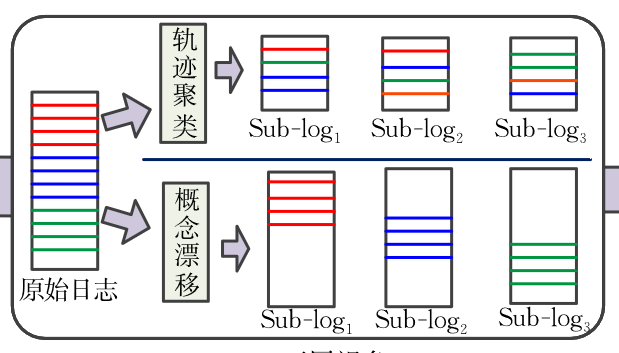
- 轨迹聚类(trace clustering):为了解决模型过于复杂的问题,可以利用轨迹聚类,将相似的业务行为聚为一个子日志,每个子日志刻画的是原始模型局部的行为。
- 目的:降低了模型的复杂度
- 对象:模型的静态结构
- 方法:利用相似的业务行为进行聚类
- 概念漂移(Process Drift):为了解决因多个版本混在一起导致的挖掘模型不正确的问题,可以对日志进行概念检测,通过检测到的变化点将日志划分为多个子日志,每个子日志刻画的是业务流程的一个版本。
- 目的:解决了由于业务演化带来的挖掘模型不正确问题
- 对象:模型的动态演化过程,行为的变化
- 方法:通过发现行为的变化来找出日志的漂移点(也称变化点),进一步利用漂移点将日志划分为不同子日志,从而得到业务过程的不同演化版
未来方向
- 算法层面:更加全面的流程轨迹表示方法,现有的轨迹刻画无论是字符串还是轮廓,都是人为赋予的表示方法,带有主观性。如果能更加客观且全面地表示出轨迹内容,则聚类效果会更上一层楼。这个方向可以借鉴机器学习方向的相关工作,如NLP中的词向量表示方法等。
- 策略层面:提出新的结构,更好地融合距离驱动和模型驱动聚类
- 应用层面:目前的流程轨迹聚类方法主要用于优化流程发现得到的模型结构,而没有考虑时间维度。可以考虑时间维度的模型演变,结合概念漂移,实时监测随着时间偏移、版本更新,轨迹类簇的动态变化趋势。
研究方法
主要可以分成距离驱动、模型驱动和混合聚类方法
基于距离驱动的聚类方法
-
方法
1)对日志轨迹进行刻画,将轨迹中的特征表示出来(如轨迹轮廓,traces profile)
2)通过编辑距离等方法计算出轨迹之间的相似度
3)基于传统的聚类算法将轨迹划分为不同的类
-
分类
- 具体型:不对轨迹做任何转换,直接在轨迹上计算相似度。如将轨迹看成字符串后,使用最小编辑距离计算轨迹之间的相似度再聚类。
- 抽象型:将轨迹刻画为向量,然后再基于轨迹向量计算对轨迹之间的相似度。最常用的是轨迹轮廓profile,从不同的视角来刻画轨迹向量,将所有视角的向量聚合后得到轨迹向量。
基于模型驱动的聚类方法
直接从模型出发,然后通过模型与轨迹之间的评价指标(拟合度、复杂度等)来确定轨迹属于哪个类簇。其中,训练的模型可能是直接输入的,也可能通过日志中的部分数据集间接得到的。如果是间接得到的模型,那么如何选择日志中的轨迹也是个难点(如贪心策略)
继承距离驱动和模型驱动的混合聚类方法
距离驱动的聚类算 法考虑到了每条轨迹与其他轨迹的综合信息,即全局考虑了行为的相似度。而模型驱动算法仅考虑当前轨迹与模型的评价得分,此类算法通常采用随机 策略或者贪心策略获取最优解,容易陷入局部最优。 为此,混合聚类算法综合考虑了两者的利弊,集成了两者优势对日志轨迹进行聚类
基于向量空间模型的聚类方法
-
原理:基本思路是将轨迹转换为向量空间模型,特征由以下元素定义,在这个模型中,每个轨迹被表示为一个向量,这些向量的维度由活动、过渡或k-gram的组合所决定:
- 活动(activities):即流程中执行的具体操作或步骤。
- 过渡(transitions):即活动之间的转移或顺序。
- k-gram:指的是活动的子序列,通常是k个连续的活动。
基于这些向量,聚类可以采用多种技术,如:
- 层次聚类(Agglomerative hierarchical clustering)
- K均值聚类(k-means clustering)
在计算聚类时,可以使用不同的距离度量(distance metrics),例如:
- 欧几里得距离(Euclidean distance):用于测量两个向量在几何空间中的直线距离。
- Jaccard距离(Jaccard distance):用于衡量两个集合的相似度,特别适用于集合间的比较。
-
问题
1)如何定义合适的向量空间模型(vector space model),将多个视角合并为一个统一的模型来提供更加综合的流程分析
事件日志包含了多种不同视角的数据,每种视角反映了流程执行的不同方面:
- 控制流视角(Control-flow perspective):活动的顺序或控制流,关注活动之间的顺序关系。
- 组织视角(Organizational perspective):资源的组织和分配,关注不同资源(如员工或机器)在流程中的作用和任务分配。
- 轨迹视角(Trace perspective):活动的频率,关注流程中各个活动出现的频率,帮助识别流程中频繁的操作或步骤。
- 性能视角(Performance perspective):时间性能,关注每个活动的执行时间或整个流程的执行时间,帮助发现瓶颈或效率问题。
-
特点
-
优点:这种方法的优势在于将轨迹转化为数学向量,便于进行标准的聚类分析和距离度量。
-
缺点:损失轨迹的某些细节信息
-
-
语法方法(Syntactic techniques)
第二种方法是基于“序列的原始形式”进行聚类,方法并不对轨迹进行转化,而是直接操作原始轨迹。这些方法通常应用字符串距离度量(string distance metrics),如:
- Levenshtein距离:也叫编辑距离,衡量将一个字符串转换成另一个字符串所需的最小编辑操作数(插入、删除、替换)。 - 通用编辑距离(Generic edit distance):与Levenshtein距离类似,但可能包含更多种类的编辑操作,或考虑不同操作的成本。这些字符串距离度量可以直接在标准的聚类算法中使用:
- K均值聚类 - 层次聚类等。特点:
- 优点:保留更多的序列信息 - 缺点:计算量较大,且对复杂度较高的序列处理时可能不如第一种方法高效
评估方法
基于适应度+复杂度进行评估。
基于假设:如果形成的集群是有意义的,那么由特定集群中的trace产生的过程模型应该更简单(更容易理解并且不像意大利面条那样)。
关键词
英文:
- trace clustering
- log division
- case similarity
- concept drift
中文:轨迹(日志)聚类、概念漂移(漂移 检测)+日志划分(切割)或过程挖掘(流程挖掘
综述
面向过程挖掘的日志划分技术综述
- 计算机学报 CCF-A
- 2022
- http://cjc.ict.ac.cn/online/onlinepaper/lll-202297212756.pdf
论文
Active Trace Clustering for Improved Process Discovery
-
IEEE Transactions on Knowledge and Data Engineering CCF-A
-
2013
-
数据集:
-
代码:ProM插件ActiTrac
- 依赖HeuristicsMiner算法进行流程发现,ICS-fitness来进行适应度
-
问题:传统聚类方法过于关注如何实现组内相似性高、组间相似性低的目标,而忽略了实际使用场景的目标:在轨迹聚类的背景下,这种目标是生成高质量(准确性高、复杂性低)的过程模型。即传统聚类算法并没有考虑到产生的过程模型是否足够高质量
-
方法
-
基于主动学习的思想,本文提出了一种新的主动轨迹聚类方法,通过自顶向下的贪婪算法解决问题,不依赖向量空间模型或相似性度量。目标是找到一种轨迹分布,使得各组流程模型的综合准确性最大化。
-
选择阶段:通过选择性采样策略逐步添加轨迹,创建一个满足精度要求的流程模型。选择出现频率最高的轨迹作为一个聚类簇,每次从剩余轨迹集合中选取一个轨迹加入聚类簇,使用HeuristicsMiner算法对聚类簇生成流程模型。如果模型的fitness保持高于目标fitness,则继续添加新的轨迹到聚类簇中,直到聚类模型达到指定精度并满足最小聚类大小要求,则进入下一阶段。
-
前瞻阶段:确定是否可以将剩余轨迹加入当前聚类,而不显著降低流程模型的准确性。
-
残余轨迹处理阶段:处理未被分配的轨迹,防止出现不平衡聚类。将剩余轨迹独立创建新的聚类,或根据个体轨迹对已创建的流程模型的适配度,将其分配到现有聚类中。研究中优先采用第二种方法,以避免形成大小严重不均的聚类,从而影响模型评估结果。
-
Trace Clustering in Process Mining
- BPM 2008会议
- ProM插件:Trace Clustering
- 数据集:阿姆斯特丹 AMC 医院(荷兰一家大型学术医院)的流程日志
- 方法:本文提出了一种基于轨迹(trace)聚类的方法。轨迹聚类的核心思路是将事件日志分割成多个同质性较高的子集,然后对每个子集分别创建流程模型。通过将事件日志划分为多个相似的子集,能够生成更易于理解的流程模型,从而提升复杂环境下的流程挖掘效果。
- trace表征:构建活动频次向量,再构建活动参与者频次向量(也可以理解为属性、设备 id),串联后表示这条trace的向量,用欧几里得距离来度量每两条轨迹的距离。
- 过渡轮廓(Transition Profile):此轮廓的指标项是轨迹中直接的跟随关系。例如,对于活动名称对〈A, B〉,该轮廓的指标值是“事件A之后紧接事件B”的次数。这种轮廓对于比较轨迹的行为很有用。
- 案例属性轮廓(Case Attributes Profile):此轮廓的指标项是案例的数据属性。在许多实际场景中,轨迹通常会带有元信息,可以通过该轮廓进行比较。
- 事件属性轮廓(Event Attributes Profile):此轮廓的指标项是日志中所有事件的数据属性。指标值表示轨迹中具有某一特定属性的事件数量。这种轮廓可以通过比较事件的元信息来捕捉轨迹的相似性。
- 性能轮廓(Performance Profile):与其他轮廓不同,性能轮廓具有一组预定义的指标项。例如,轨迹的大小定义为其事件数量。如果有时间戳信息,还可以进一步测量案例的持续时间,以及每条轨迹中事件间时间差的最小值、最大值、平均值和中值。
- 聚类:K-means Clustering、Quality Threshold Clustering、Agglomerative Hierarchical Clustering、Self-Organizing Map
- trace表征:构建活动频次向量,再构建活动参与者频次向量(也可以理解为属性、设备 id),串联后表示这条trace的向量,用欧几里得距离来度量每两条轨迹的距离。
Trace Clustering Based on Conserved Patterns: Towards Achieving Better Process Models
-
BPM 2009会议
-
数据集:飞利浦医疗保健日志
-
方法:提出了一种轨迹聚类方法,围绕最大重复子序列相关构建六个特征组成的特征集,将所有轨迹的保守子序列汇总得到所有轨迹的特征集,将这些特征作为向量的维度,用二进制或计数来填充向量。如果轨迹包含该子序列,则该维度为1,否则为0。使用凝聚层次聚类技术进行聚类
A Co-Training Strategy for Multiple View Clustering in Process Mining
- Ieee Transactions On Services Computing CCF-A
- 2015
- 问题:在基于向量空间模型的轨迹聚类方法中,存在多个视角,先前的研究大多单独对每个视角进行聚类。如果能够将多个视角的信息同时融入聚类过程,能够提供更精确的聚类划分,从而改善流程发现的效果。然而,问题在于直接将多个视角的特征连接成一个长向量并不合适。因为这些视角有不同的性质,简单地将它们拼接成一个高维的特征向量可能会带来“维度灾难”(curse of dimensionality)问题,即高维空间中的稀疏性可能导致聚类效果的下降。
- 数据集:Process Mining Repository中的11个数据集,涵盖了广泛的应用领域,包括 问题管理、医疗过程、贷款申请、电话修理、期刊评审 等。
- 方法:为了避免维度灾难,作者提出了一种多视角聚类方法(multiple view clustering)。
- 分别从活动、资源、性能和变迁四个视角构建相似度矩阵,采用协同训练的策略:对于每个视角,基于该视角上一轮得到的聚类矩阵和其他视角的相似度矩阵,更新该视角的相似度矩阵,根据所有视角的聚类结果计算平均的轮廓系数,如果不再提高或达到最大迭代次数,则停止迭代。
- 如何将迭代完成后的多个视角的聚类结果进行整合,得到最终的共识聚类结果:对于所有视角计算的相似度矩阵,我们将它们加和并归一化,得到一个共识相似度矩阵。这个矩阵代表了所有视角中,轨迹间的整体相似度,基于该矩阵进行聚类将产生一个综合所有视角信息的最终聚类结果。
- 评估聚类生成簇的重要性:使用 ProM 框架中的 Alpha++ 挖掘生成流程模型,计算复杂性相关指标并进行一致性检查
-
act2vec, trace2vec, log2vec, and model2vec: Representation Learning for Business Processes
- BPM 2018 高引用
- 2018
- 方法:通过NLP中词向量的表示方法,将轨迹或者日志片段表示为向量
Retrieval and clustering for supporting business process adjustment and analysis
- Information Systems CCF-B
- 2014
- 方法:作者考察实际日志发现很多活动的属性是无法量化的,如内容相同但名称不同、活动之间存在重叠等。因此,定义了近邻图距离(neighbors graph distance)来计算轨迹之间的相似度,最后使用非加权组平均法进行层次聚合
流程异常检测
背景知识
业务流程过程中的异常情况可以分为行为异常、时间异常和属性异常3类。
- 行为异常:从控制流视角出发,主要关注活动执行顺序的正确性,如流程执行过程中由于某个错误的操作而导致活动被重复执行;
- 时间异常:从时间视角出发,主要关注活动的持续时间以及实例总的执行时间是否合理,如当活动执行的持续时间是平时的几倍或实例的总执行时间超过预期等;
- 属性异常:从其他属性值出发,主要关注属性状态是否正常,如从资源属性上看,若活动a被从未执行过它的资源执行,这就属于偏环离原有预设的行为,将被视为属性异常情状况。
传统的业务流程异常检测通常借助一致性检查技术来实现,即通过将日志中记录的执行趋势与标准的参考流程类型进行对齐,进一步检测是否存在异常。该类方法需要借助一个标准的参考流程模型,用于表征流程中全部的正常执行情况。
同时,大多传统一致性检查技术仅关注控制流。
分类
-
基于流程挖掘的业务流程异常检测方法(传统一致性检验算法)
1)原理:通过流程发现从事件日志中提取流程模型,进一步进行一致性检验。例如:基于token重演、基于alignment
2)缺点:
- 只能检测控制流级别的异常,不能检测属性级别的异常
- 依赖数据集质量,数据集中不能存在任何异常轨迹:难以实现,因为数据集中总是会存在一些异常的
- 过于严格,假阳性率高
-
基于机器学习的一致性检验算法
-
监督:因为标记数据获取困难,所以比较少见
-
无监督(主要)
-
半监督
-
-
基于深度学习的一致性检验算法
原理
-
通过流程发现从事件日志中挖掘出流程模型,然后通过一致性检查来检测异常行为
缺点:不利用事件属性,因此不能检测属性级别的异常
-
基于似然图(likelihood graph)的方法:将事件属性融入一个扩展的似然图,以包括流程的重要特征,从而能够更加全面地刻画流程行为。
-
优势:将事件属性纳入模型中,使得检测异常时不仅能考虑到事件的顺序,还能分析属性层面的异常。
-
缺点:尽管似然图方法更具灵活性,但它依赖于属性连接到图中的离散顺序,这可能会带来偏差。也就是说,不同属性之间的顺序关系可能会影响图的结构,从而对检测结果产生一定的偏向性。
-
局限性
-
基于流程挖掘的业务流程异常检测(一致性检验)
挖掘过程模型、轨迹对齐与托肯重演等操作需要占用大量资源且效率较低。
-
基于ML的业务流程异常检测
- 数据集:难以获取全面的标记数据(异常行为的种类太多,难以全面覆盖)
- 在事件日志特征工程中过于依赖专家知识去手动添加特征,泛化能力差。
- 仅实现片面的单一维度特征提取,且事件日志中轨迹间隐含的复杂关系未能显式呈现并进行特征抽取,难以实现全面准确的
关键词
-
流程异常检测 process anomaly detection
-
流程聚类 trace clustering
-
异常检测 Anomaly detection
-
合规性检测 conformance checking
-
“process mining” AND “anomaly detection”
-
业务流程异常检测 business process anomaly detection
-
离散序列异常检测 Discrete Sequences Anomaly Detection
离散序列是指由一系列按照特定顺序排列的离散事件或符号构成的序列。每个事件通常来自一个有限的符号集,并且在序列中具有顺序关系。离散序列在许多领域中很常见,比如网络日志、机器操作记录、用户行为轨迹等。
例子:假设我们有一家电商网站的用户操作日志,其中每个用户的操作可以是“登录”(Login)、“查看商品”(View)、“加入购物车”(Add to Cart)、和“结账”(Checkout)。我们可以将这些操作记录为一个离散序列。
综述
流程挖掘一致性检验算法研究综述
- 2023
- 流程挖掘一致性检验算法研究综述_赵百威.pdf
总结了一致性检验算法,包括:基于token重演的一致性检验算法,基于日志中活动行为模型的一致性检验算法和基于模型和日志对齐的一致性检验算法。
Conformance checking: A state-of-the-art literature review
- 2019 高引用
- 总结了流程挖掘领域的一致性检验算法
论文
基于上下文感知的多角度业务流程在线异常检测方法
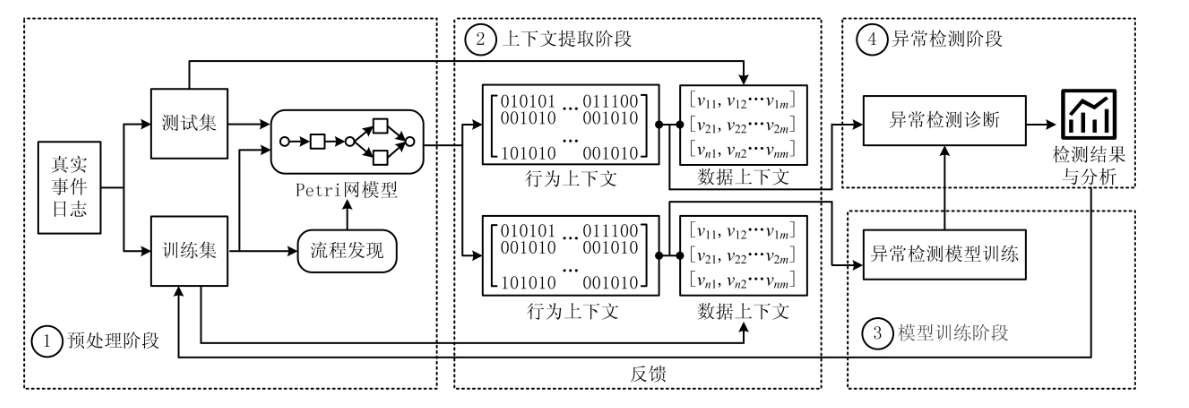
- 2021
- 数据集:Helpdesk和BPIC2012,手动生成异常标记
- 方法:
- 模型训练:对训练集使用流程发现算法构建Petri网模型表征业务流程,采用轨迹重演的方法提取行为上下文(控制流视角,包括事件的全局和局部行为),数据上下文信息(数据流视角,包括时间和属性),将每个事件的上下文信息向量(即上面提到的四个向量)级联得到该事件的编码向量,输入LSTM训练异常检测模型。
- 异常检测:对待检测的轨迹进行上下文提取,然后将其编码为相应的数据形式并输入到训练得到的异常检测模型中最后,检测模型的输出结果将被发送给相关人员用于决策,同时最终的成绩结果和当前的成绩数据将被保存下来用于检测模型类型的增量更新,以提高检测模型的准确性
基于注意力机制的业务过程异常检测方法
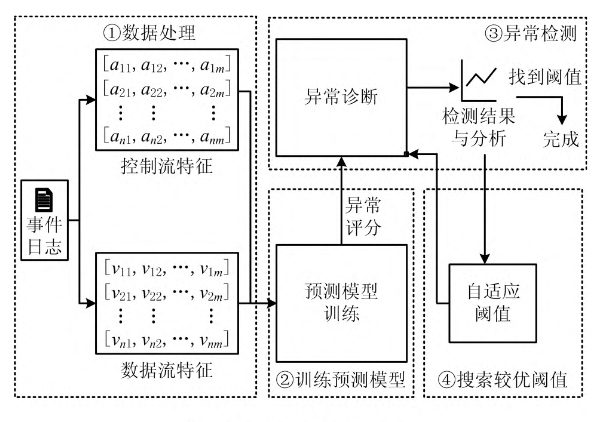
-
2021
-
论文:基于注意力机制的业务过程异常检测方法_孙晋永
-
方法:
提取事件日志中的控制流特征和数据流特征,输入构建的Transformer模型(适合处理具有长距离依赖、存在重复出现子序列的业务过程的事件序列,注意力机制能够捕捉长期和短期的事件或事件属性的依赖关系),得到异常评分并设置阈值。
不需要从事件日志中挖掘出过程模型,不需要领域知识,也不需要对事件日志进行手动标记的方法
Balanced multi-perspective checking of process conformance
- Computing 中科院三区 高引用
- 2016
- 问题:传统的合规性检查方法主要专注于控制流(control flow),即事件和活动的顺序、流向等,忽略了数据依赖(数据的输入输出关系)、资源分配(谁执行哪些任务)以及时间约束(任务执行的时间要求)。即使考虑到其他视角,也会是优先考虑控制流视角,这导致其他视角只是作为次要因素进行考虑
Deep reinforcement learning for data-efficient weakly supervised business process anomaly detection
-
J Big Data 中科院二区
-
2023
-
问题:因为标记数据的难以获取,业务流程异常检测领域的大部分方法聚焦在无监督学习上面。但是因为无监督学习仅依赖于异常分布的假设,缺乏对真实异常的先验知识。同时目前的半监督方法不适用于新异常行为的检测。
-
研究内容:
- 首次将深度强化学习方法来检测业务流程领域异常的
BINet: multivariate business process anomaly detection using deep learning
- International Conference on Business Process Management 高引用
- 2018
Anomaly detection for industrial control systems using process mining
- COSE CCF-B
- 2018
内部威胁检测
论文
Log2vec: A Heterogeneous Graph Embedding Based Approach for Detecting Cyber Threats within Enterprise
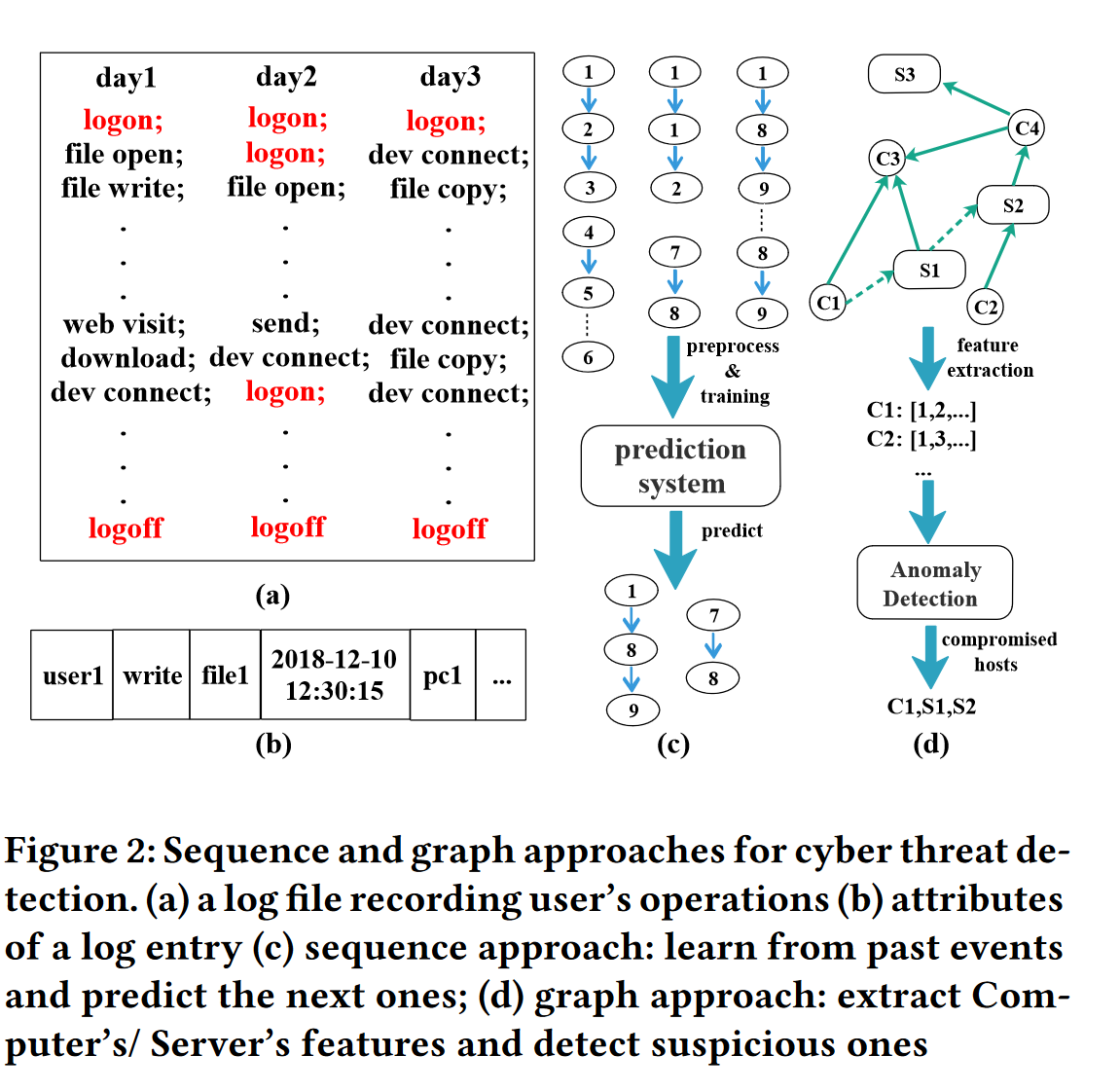
-
CCS 安全四大顶会
-
2019
-
问题:
-
数据集:CERT r6.2、LANL
-
代码:未开源
-
研究问题
信息系统在当代企业中至关重要,但面临多种威胁,其中包括:
- 内部威胁(Insider Threats):由拥有合法访问权限的内部员工发起的攻击,他们可能利用权限破坏系统的机密性、完整性或可用性。
- 高级持续性威胁(APT):外部攻击者通过初始账户或主机的漏洞进入系统,随后利用网络内部横向扩展并窃取机密数据。
这两种攻击对现代企业的威胁严重且代价高昂。现有方法基于用户行为建模(例如将日志操作转化为序列,利用深度学习进行预测),误报高,局限大
-
研究内容
本文考虑日志条目中的顺序、逻辑、交互关系,将日志数据建模为异构图,利用图嵌入技术,将异构图中的日志操作转化为高维向量(操作表示),将异常的日志操作聚类到单独的群组中,辅助识别恶意操作。
-
局限性
- 图规则仅仅针对内部威胁和APT两种场景,但是还存在其他的攻击场景,需要构建新的图规则来将新的关系纳入异质图中
- 误报率高,考虑采用combating threat alert fatigue方法对抗
- 图嵌入和检测算法的优化,如考虑使用GNN等来进行图嵌入等
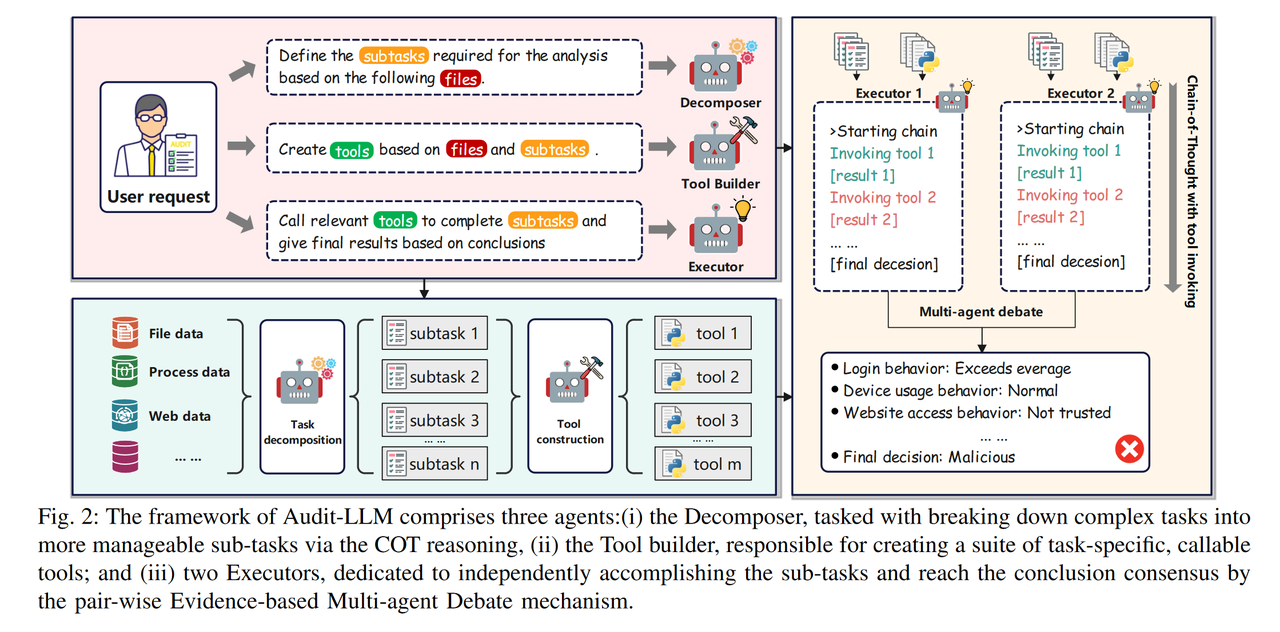
Audit-LLM: Multi-Agent Collaboration for Log-based Insider Threat Detection
- preprint
- https://arxiv.org/pdf/2408.08902
- 问题:
- 多样化的活动类型和过长的日志文件为LLMs直接识别恶意活动带来了显著的挑战,因为它们需要从众多正常活动中筛选出恶意的行为
- LLMs的“信任幻觉”问题加剧了其在ITD中的应用难度,因为生成的结论可能与用户命令和活动上下文不一致。
- 研究内容:
论文提出了一个多代理日志内部威胁检测框架Audit-LLM。这个框架包括三个协作代理:
(i) Decomposer代理,使用连锁思考(COT)推理将复杂的ITD任务分解成可管理的子任务;
(ii) Tool Builder代理,为子任务创建可复用的工具,以克服LLMs的上下文长度限制;
(iii) Executor代理,通过调用构建的工具生成最终的检测结论。
 wechat
wechat