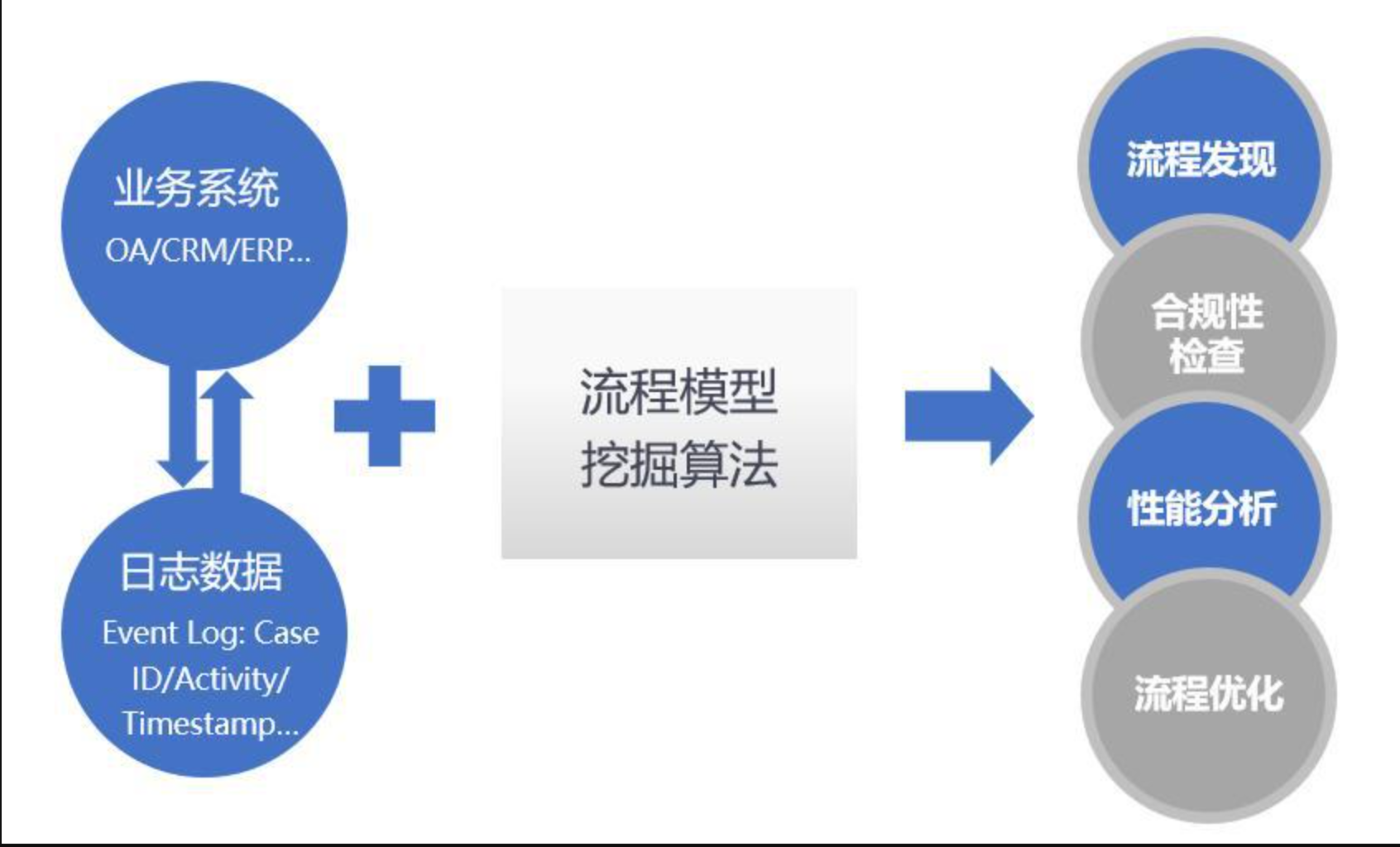
『科研』流程挖掘领域关键技术总结
实验室最近的项目需要基于流程挖掘进行日志异常检测任务,本文主要记录在项目研究过程中,对流程挖掘领域的关键技术研究总结。
流程挖掘基础知识
XES日志
什么是事件日志:L= [<a,e>^10 ,<a,b,c,e>^5, <a,c,b, e>¹],次方表示的对应轨迹在日志中出现的次数。
XES (eXtensible Event Stream) 是一种基于XML的事件日志标准。它旨在定义一种不同工具和应用领域下交换日志文件的格式。XES主要用于过程挖掘,但同时也可以用于广义数据挖掘、文本挖掘和静态分析。
-
元模型
XES文件以XML格式编写,包含一个或多个事件日志(
log),每个日志包含多个流程实例(trace),而每个流程实例包含一系列事件(event)。- Log:顶级节点,表示日志,包含多个Trace,即某些具体路径的集合。
- Trace:二级节点,表示一个具体的路径,包含多个Event,即具体事件的集合。
- Event:三级节点,表示一个具体的事件。
例如,在一个访问网站的日志中,Log表示访问网站,Trace表示某个具体的用户的某次访问网站的过程,Event可以表示诸如“浏览器下载一张图片”的事件。
-
拓展extension
标签用于定义日志中使用的扩展,常见的扩展有:
Concept:用于描述流程概念,例如事件名称。Lifecycle:表示事件的生命周期状态(如“start”、“complete”)。Time:用于定义时间戳信息。
-
属性Key
XES本身不具有对任何特定工具和应用领域的预定义。它们需要通过定义扩展,即Extension以及属性Attribute来进行表达。XES支持的属性类型包括字符串、日期、整型、浮点型、布尔、ID(即唯一值)等,同时它支持属性的嵌套。 XES使用Classifier标签对事件分类。
- **全局属性global:**global元素用于定义事件日志中所有实例或事件共享的属性,可以是
trace或event作用域。 - 属性类型:包括string、date等
- 属性值:在key标签中,key表示属性名,value为属性值
- **全局属性global:**global元素用于定义事件日志中所有实例或事件共享的属性,可以是
-
classifier
classifier标签用于定义事件分类的方式,如按“活动”分类(Activity),分类器指定了如何根据一个或多个键将事件分组。
流程挖掘方法
学习参考:流程挖掘- CSDN搜索
-
定义
流程挖掘(PM,Process Mining)是从现有事件日志中挖掘知识以发现、监控和改进实际流程。流程挖掘从事件日志中挖掘实际流程的潜在知识和信息,可以把流程挖掘归类为数据挖掘。然而,很多数据挖掘方法并没有对实际流程的事件日志进行挖掘的研究,因此流程挖掘弥补了这一缺口。
从流程挖掘的定义来看,流程挖掘并没有限定你使用什么方法,只要是对实际流程的事件日志挖掘知识和信息,不管你是用过程发现(PD,Process Discovery)算法、一致性检验(CC,Conformance Checking),还是用决策树算法、关联规则分析等,都可以说你是在流程挖掘。因此,流程挖掘确实就是数据挖掘在流程层面的数据上的应用,当你打算在流程数据上做分析,或者你的工作本身就是与流程和流程数据打交道,流程挖掘的方法和数据挖掘的方法都是值得学习和使用的。(数据挖掘的方法一样可以应用于流程挖掘上面)
-
分类
1)过程发现(Process Discovery)
根据事件日志数据创建流程模型,不需要先验知识
2)一致性检验(Conformance Checking)
在已经构建一个标准流程模型(理想情况)的情况下,希望确保实际执行的流程符合这一标准。通过将实际生成的流程模型(依据日志中记录的执行轨迹)与预期的流程模型进行对比,识别出不一致的地方。
缺点:
- 如果不存在标准流程模型,则需要借助过程发现技术从事件日志中挖掘挖掘流程模型,但因为真实应用场景下的日志中通常包含异常执行信息,所以挖掘得到的日志并不完全标准
- 一致性检查技术大都只能从控制流的角度观察异常,即流程中活动的执行顺序没有出现异常,而忽略了存储在日志中根据大量的其他相关数据,这些数据可能存在某些难以发现的潜在风险。
3)过程改进(Process Enhancement)
借助实际流程记录的事件日志中得到的知识和信息,来扩展或改进现有流程(先验模型)的方法。
-
挖掘的视角
流程挖掘针对事件日志的三种不同的挖掘视角:
- process perspective:流程视角侧重于控制流,即活动的顺序。挖掘这一观点的目标是找到所有可能路径的良好表征,例如用 Petri 网来表示。
- organizational perspective:组织视角侧重于发起者领域,即哪些执行者参与执行活动以及他们之间的关系。目标是通过根据角色和组织单位对人员进行分类来构建组织,或者显示个体执行者之间的关系。
- case perspective:case视角将每一个case看成一个整体。案例视角侧重于案例的属性。案件可以通过其在流程中的路径或处理案件的发起者来表征。案例也可以通过相应数据元素的值来表征。例如,如果一个案例代表医院中患者的特定治疗,那么了解吸烟者和非吸烟者之间的处理时间差异(整个case执行所需要的时间)是很有趣的
流程模型
-
定义
流程模型是表示流程的语言,包含控制流式流程模型和声明式流程模型。流程模型包含正式模型和非正式模型。正式模型也称为可运行模型,用于分析和启动;非正式模型用于讨论或文档化。
- 案例(Case)
是指从流程起到到流程终点的一次运行实例,案例具有案例ID(Case ID),有案例层面的属性,有执行流程的活动轨迹。 - 轨迹(Trace)
是一串活动序列,是一个案例的执行痕迹,序列中每个元素是案例发生的事件。 - 事件(Event)
是活动的发生,事件的基本属性有案例ID、活动名称和时间戳,分别指示所属案例、所属执行的活动和执行顺序。事件可以有其他附加属性。
- 案例(Case)
-
分类
过程模型的目的在于决定什么活动需要执行、以何种方式执行。
从控制流的角度分析过程,实际活动可以顺序执行,可以选择执行或并发执行,同时相同活动的重复执行也有可能发生。针对不同类型的流程可以构建不同的流程模型。
- 有向图(DFG)
- Petri网
- 流程树(Process Tree)
接下来介绍几个常见的流程模型
Petri网
Petri网是一种用于描述和分析离散事件系统的数学模型,可以对业务流程进行可视化建模,应用于流程挖掘。可以描述系统的动态行为。
-
基本组成
N = (P,T,F)- 库所(Places):用圆圈表示,代表系统中的状态或条件。每个库所可以包含一定数量的标记(tokens),标记的数量表示当前系统的状态。
- 变迁(Transitions):用矩形或条状方块表示,表示系统中可能发生的事件或动作。当变迁触发时,系统会从一个状态转移到另一个状态。
- 弧(Arcs):连接库所和变迁,用箭头表示,表示库所和变迁之间的关系。弧表明哪些库所会影响哪些变迁的触发,或哪些变迁会导致哪些库所发生变化。
- 标记(Tokens):表示系统当前的状态,通常放置在库所中。标记可以通过变迁的触发在库所间移动,从而反映系统状态的变化。
-
工作原理
在Petri网中,变迁触发的条件依赖于其前置库所是否有足够的标记。当变迁满足触发条件时:-
它会消耗前置库所中的标记。
-
然后在与其后置库所相连的库所中生成标记。
-
系统的状态因此发生变化。
这种标记的传递和变迁的触发描述了系统的动态行为。
Petri网模型在流程发现时会整合所有日志中的路径,如果日志中存在异常操作或不同用户权限会导致产生的流程模型存在噪声:
-
日志中存在异常数据:预处理清洗或者使用聚类,分离出异常的日志
问题:低频路径可能被误判为异常,采取频率分析
-
权限、角色:不同的用户权限或角色会导致不同的操作路径。例如,管理员可以直接跳过审批步骤,普通用户则需要走审批流程。这些权限差异会使得Petri网模型包含过多分支和变体,从而增加异常检测的难度。
- 基于角色生成不同模型:可以根据角色或权限先对事件日志进行划分,分别生成每个角色特有的Petri网模型。这种方法能确保每个角色的模型只反映对应权限下的正常操作路径,使得异常检测更加准确。
- 使用带标签的Petri网(Colored Petri Net):彩色Petri网是一种扩展版Petri网,可以在库所或变迁上添加不同的颜色标签来表示不同的角色或权限。这样,模型不仅包含操作流程,还能体现权限/角色的不同。异常检测时,如果流程中发生了不符合权限的路径变迁,就会标记为异常。
-
-
特性
Petri网具有一些独特的特性,使其特别适用于并发系统的建模和分析:
-
并发性(Concurrency):多个变迁可以同时触发,支持并发行为的建模。
-
同步性(Synchronization):多个前置条件必须满足才能触发一个变迁,适合描述多个事件同步发生的情况。
-
异步性(Asynchrony):事件可以独立地触发而不影响其他事件的发生。
-
非确定性(Non-determinism):当多个变迁在同一时间点可以触发时,系统会随机选择一个变迁进行触发。
-
transition system
transition system(变迁系统)是一种基础的过程建模方法,它是一种有向图,由状态和变迁组成,节点代表状态,边代表着状态的转化。
- 优点:简单
- 缺点:没办法体现并行任务,系统中出现并行任务的时候会造成状态爆炸问题
BPMN
BPMN(Business Process Modeling Notation,业务流程建模与标注)已经成为使用最广泛的业务过程建模语言之一。被许多工具提供商支持,并由OMG制定标准。
Process tree
-
定义
一种块结构的流程模型,它是以一种树的形式呈现给用户,其中树的结点由流程树运算符和事件活动组成,叶子节点为事件日志中的活动,非叶子节点则是流程树运算符的集合,流程树运算符包括顺序,排他,并发,循环四种,具体的解释如下:
1
X: 排他运算符; -> : 顺序运算符; Q : 循环运算符; ^ : 并发运算符
-
排他运算符的规则为一个子过程A与另一个子过程B两个之间没有任何关联,一个子过程A中的活动的后继活动不能在另一个子过程B中,一个子过程B中的活动的后继活动不能在另一个子过程A中,两者互不关联。
-
顺序运算符的规则为从一个子过程A到另一个子过程B有出边,但是无入边,两者总体上只有一方到另一方。
-
并发运算符的规则为一个子过程A既有到另一个子过程的出边,也有另一个子过程B到这个子过程A的入边。两者彼此交叉,并行存在。
-
循环运算符的规则为一个活动从子过程A出发,到达另一个子过程B中,再由B重现回到A。总结为:起于此终于此。
-
-
优势
在实际执行中,作为块结构模型(block-structured models),分层流程模型,BPMN 不受 控制流复杂性增长的严重影响,具有良好的可读性和可维护性,便于流程的设计、沟通与自动化执行。
-
缺点
petri和BPMN此类基于图的模型均存在以下的问题:
1)死锁(Deadlock)问题
假设有一个简化的审批流程模型,涉及两个任务:
-
任务A:由主管审批。
-
任务B:由财务审批。
在这个模型中,规定只有在主管审批完成后,财务才能进行审批,反之也需要财务审批通过后,主管才能审批。我们可以将这个逻辑用Petri网或其他流程模型表示出来,形成一个环形等待关系。
- 执行中:当流程执行到这一步时,主管等待财务的审批完成才能继续,财务也等待主管的审批完成才能继续。这种相互依赖关系导致了一个死锁,因为没有人能首先完成审批,流程将永远停滞在此步骤,无法继续下去,任务也无法完成。
这种情况在流程模型中很常见,尤其是设计复杂的流程或涉及多方审批时,若没有仔细定义优先顺序或解锁条件,很容易形成死锁。
2)活锁(Livelock)问题
假设有一个仓库补货流程,简化为以下两个步骤:
-
步骤1:检查库存。
-
步骤2:检查供应商是否能发货。
如果库存不足,则需要去供应商那里补货,而供应商检查时发现他们需要仓库确认库存需求,于是仓库再进行检查库存,发现仍然不足,又需要再次请求供应商。由于两个步骤相互依赖,每次执行的条件又彼此触发,流程就会在这两个步骤之间循环,进入一个无限的循环,形成活锁。
- 执行中:仓库与供应商之间会不断地重复同样的步骤,每次都是重新检查库存和供应状态,但从未真正达成任何实质性的补货。这种情况下,流程被困在一个循环中,看似有活动在进行,但实际上任务永远无法完成。
-
流程挖掘领域参考资料
-
https://promforum.win.tue.nl/:流程挖掘的论坛,里面可以提出问题,这个论坛就是流程挖掘之父创办的,里面一些基本问题都是可以回答的。
-
https://github.com/promworkbench:这个里面有基于ProM框架实现的一些算法,都是开源的,可以根据需要看看
-
https://processintelligence.solutions/ :一个开源的Python库,里面包括了BPMN等流程模型的实现及可视化界面
- PMTk:一个面向最终用户的工具中包含多种流程挖掘功能,包括流程发现、流程可视化分析和一致性检查。
- PM4py:供学术界和工业界使用,是用 Python 编写的领先的开源流程挖掘库。
-
https://github.com/TheWoops/awesome-processmining:收集了部分流程挖掘相关的资源
-
https://leemans.ch/visualminer/home/ visual miner的实现,一种流程挖掘算法
-
Process Mining Handbook-2022:目前比较新的流程挖掘手册,内容比较多,选取自己需要的部分看就行。里面分模块进行了介绍然后搭配了一些相关论文,可以看看是否有可以借鉴的地方
流程发现算法
传统算法
直接算法
直接算法的基本思想是直接对事件日志进行全盘扫描, 从中找出具有特定规律的模式。
α 算法和相关改进算法是此类方法的典型代表
Alpha算法:
-
基于事件日志中活动之间的直接因果关系、并发关系和顺序关系,构建模型,可以用petri网表示。
-
主要步骤
Step 1️⃣:从事件日志中提取活动集(A)
- 收集所有出现在日志中的活动,构成活动集合 A。
Step 2️⃣:识别直接跟随关系(→)
- 比如:如果在某些轨迹中活动 A 总是直接出现在 B 前面,则认为 A → B。
Step 3️⃣:识别不同类型的关系
- 顺序(A → B)
- 并发(A || B,A 和 B 可交换)
- 无关(A # B,A 和 B 没有直接联系)
Step 4️⃣:构造“前集-后集”的模式
- 推断可能的起点、终点,以及中间的连接结构(例如:{A} → {B, C})。
Step 5️⃣:生成 Petri 网(或其他模型)
- 将关系映射为 Petri 网元素,构建模型
-
特点
1)优点:简单、成熟
2)缺点:不能处理复杂结构和噪声
-
α 算法的应用需要一个重要前提, 即日志完备且没有噪声。Alpha算法通过分析事件日志中的活动顺序来识别活动之间的关系。它依赖于“直接跟随”关系来推导出活动间的因果关系、并行关系和其他依赖关系。如果日志数据缺失或记录错误,这些活动之间的顺序关系将不准确,导致错误的关系推断。
-
不能处理不明显的依赖关系。Alpha算法只识别明显的直接关系,对于间接关系或复杂的依赖结构处理不足。例如,如果某个活动的发生依赖于多个其他活动的组合,Alpha算法可能无法正确识别这种复杂的依赖。
-
并行活动的处理: 对于并行活动的处理,Alpha算法可能将实际上是顺序或选择关系的活动误判为并行关系。这是因为算法认为如果活动A直接跟随活动B,且B也直接跟随A,那么这两个活动是并行的。然而,这种简单的规则可能无法准确识别真正的并行关系。
Alpha+算法解决了这个问题
-
无法处理循环结构: Alpha算法的基本版本不支持处理日志中的循环结构
例如:假设我们有一个简单的工作流,其中包括三个活动:A, B, 和 C。活动流程如下:
活动A开始,之后过渡到活动B。
活动B完成后,可以返回到活动A,形成一个循环。
活动B也可以过渡到活动C,然后结束。
这个工作流的活动日志可能看起来是这样:
- 案例1: A, B, A, B, A, B, C
- 案例2: A, B, C
- 案例3: A, B, A, B, C
在这个例子中,活动B之后直接跟随两种活动:A(循环回去)和C(继续往下执行)。根据Alpha算法:
- 活动B直接跟随活动A和活动C,反之,活动A也直接跟随活动B。
- 这导致算法可能会推断出A与B之间可能存在并行关系(因为A和B相互直接跟随),这显然是错误的。
-
短路循环和长距离依赖: 短路循环(即循环迭代次数非常少的情况)和长距离依赖(活动之间的依赖关系在日志中不频繁或间隔很远)也是Alpha算法难以处理的。这些情况下,由于算法依赖频繁和近距离的活动模式,可能无法形成正确的因果关系。
-
可扩展性问题: Alpha算法在面对大型数据集或高复杂度的日志数据时,性能可能会显著下降。算法的时间复杂度和空间复杂度会随着活动类型的增加而显著增加。
-
Heuristics Miner(启发式挖掘算法)
-
基于一种假设:噪声日志在正确日志中所占的比例很小。启发式算法的基本思想是基于此基本假设, 在挖掘事件日志时, 考虑流程实例出现的频率, 从概率统计的角度识别噪声, 通过设定阈值, 将低频实例作为噪声过滤掉。
-
主要步骤
Step 1️⃣:构建频率表(频次矩阵)
- 统计日志中各活动对(A→B)的出现次数。
Step 2️⃣:计算活动节点之间的依赖度(Dependency Measure)
-
比如:

-
这个值表示 A 导致 B 的可能性。
Step 3️⃣:设置阈值过滤
- 去除低频路径或不可靠的关系,降低噪声影响。
Step 4️⃣:构建依赖图(Dependency Graph)
- 用边权表示活动之间的依赖强度,构建带权有向图。
Step 5️⃣:从依赖图生成模型
- 通常构造流程图(或转换为Petri网),形成可视化模型。
-
模型结构
边上面的数字表示权重,反映了所连接的两个事件之间关系的强度或依赖度。最直观一般用频率来表示权重,即一个活动直接跟随另一个活动出现的次数。这个数字说明在过程中,一个活动(A)完成后紧接着启动另一个活动(B)的实例数量。
-
特点
- 优点:解决了噪声处理问题
- 缺点:易误删低频有效行为,导致挖掘模型不能反映实际情况
基于概率统计的方法
-
原理:概率、统计学以及随机过程理论,以处理不确定性、复杂的依赖关系以及流程中的随机性。
-
分类
- 马尔可夫 (Markov) 模型
- 随机活动图 (SAG) 算法
- 增量分析
- Apriori 算法
- 随机 Petri 网等
-
特点:
1)优点:与 Alpha 算法和启发式算法等专注于流程建模不同,概率统计方法在流程挖掘中侧重于流程优化和异常检测,帮助识别流程中的缺陷,提高流程的效率和合规性。这些方法不仅可以发现高效的活动组合,还能够量化并检测异常路径,从而发现和解决流程中的潜在问题。
2)缺点:适用性不大,依附性强
Inductive Miner(归纳式挖掘方法)
-
原理:将日志分解成可解释的子日志,逐步递归地构建出流程树。
-
主要步骤
Step 1️⃣:构建直接跟随图(Directly-Follows Graph, DFG)
- 分析日志中事件的前后关系,构建一个图表示活动之间的直接关系。
Step 2️⃣:递归分解(Detect Cut)
- 判断 DFG 是否可以拆分为以下结构之一:
- 顺序(Sequence)
- 并发(Parallel)
- 选择/分支(XOR)
- 循环(Loop)
- 如果可以,就将日志拆分成子日志,并继续对子日志做相同处理(递归)。
Step 3️⃣:构建流程树(Process Tree)
- 每次切割都作为树的一个节点,最终构建出一棵包含控制结构的流程树。
Step 4️⃣:转化为模型(如Petri网)
- 最后将流程树映射为具体的模型表示,用于可视化或后续分析。
-
优点:高鲁棒性,能够处理复杂流程,发现结构良好、块结构清晰的流程模型。支持顺序、并发、选择、循环等结构,且天然保证模型的结构正确性和可解释性。
基于机器学习的方法
此类流程算法主要来自于数据挖掘相关技术在流程挖掘领域的应用, 相比于传统流程挖掘算法, 此类技术的整体成熟性还不够, 大部分还未能达到很好的挖掘效果
基于智能优化的流程挖掘算法
-
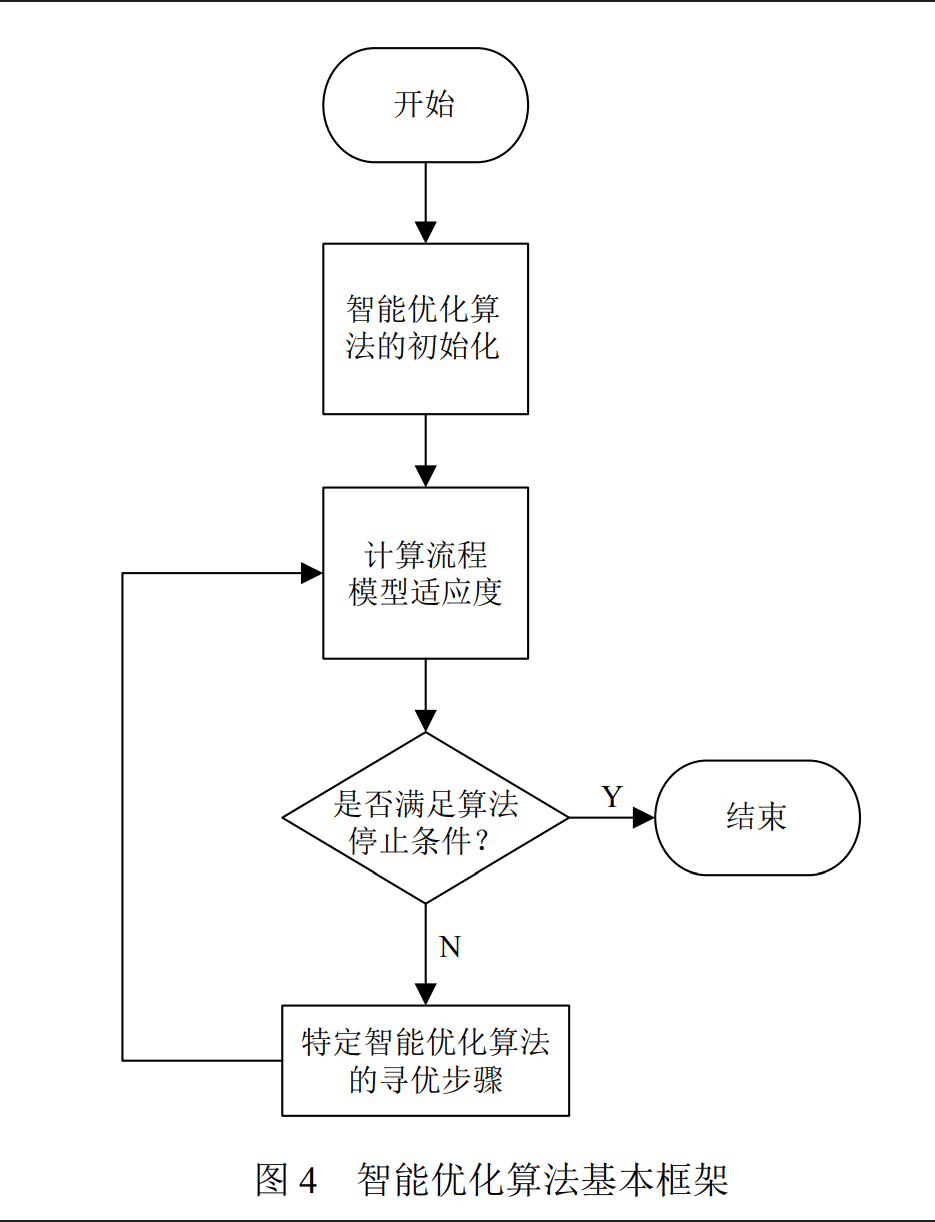
-
特点
1)优势
- 可以处理大多数的控制流结构,准确率高
- 鲁棒性好,可以很好的处理噪声
- 基于局部次序关系的全局搜索,有利于得到全局优化的结果
- 适应度函数的自由设置, 便于得到更符合用户倾向的流程模型
2)缺点:算法效率太低, 容易产生死锁等问题, 可在质量和效率两方面进行改进
-
方法
- 遗传算法
- 模拟退火算法
- 禁忌搜索算法
- 粒子群
模糊挖掘
-
原理:传统流程挖掘技术有很多显现或者隐含的假设, 使其在结构化流程上表现良好, 但应用于结构化程度低的流程, 无法提供具有洞察力的模型。这不是说传统技术挖掘的模型不正确, 而是挖掘的模型显示了所有细节, 没有从事件日志本身提供任何有意义的抽象, 因此对于流程分析师来说是无用的。
-
流程:
- 使用已有控制流挖掘算法挖掘出业务流程的 控制流模型
- 识别过程模型中的决策点。以 Petri 网为例, 若 Petri 网中某一库所对应了多个 输出弧, 则可被判定为决策点。
- 使用决策树分析过程模型中的决策点。在对过程模型中的决策点进行识别之后, 需要判定过程实例的数据属性是否对实例的决策产生影响, 即决策规则挖掘, 其思想就是将每一个决策点转换为一个分类问题, 具体类别则是作出的不同决策
-
特点:
1)优点:可以处理复杂的流程结构
2)缺点:需要找到高适应性的默认参数设置或易操作的合理参数,费时费力
决策挖掘
- 原理:事件日志中包含着大量的事件属性信息, 如时 戳、执行者和一些附加数据等, 目前的流程挖掘算法 更多的是利用前两个属性来构造反映因果相关性的流程模型, 即基于控制流视角的流程发现, 而对日志中其他数据利用较少, 无法解释活动为何被选择执行。
决策挖掘通过决策树分析技术分析日志中的各种数据信息如何影响具体的流程实例进行决策, 即得到决策规则, 关注流程挖掘的案例视角
 wechat
wechat