『模糊测试』使用AFL进行模糊测试
模糊测试简介
模糊测试(Fuzzing),是一种挖掘软件安全漏洞、检测软件健壮性的黑盒测试方法,是目前软件测试、漏洞挖掘领域的最有效的手段之一,特别适合用于发现0Day漏洞。
其主要原理在于:
- 通过随机或是半随机的方式生成大量数据,
- 将生成的数据输入给被测试的系统
- 检测被测系统的状态,如是否能够响应、响应是否正确等
- 根据被测系统的状态判断是否存在潜在的安全漏洞。
目前比较成功的Fuzzer(执行模糊测试的程序)有AFL、libFuzzer、OSS-Fuzz等。
AFL简介
AFL(American Fuzzy Lop)是由安全研究员Michal Zalewski开发的一款基于覆盖引导(Coverage-guided)的模糊测试工具,它通过记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率。
原理
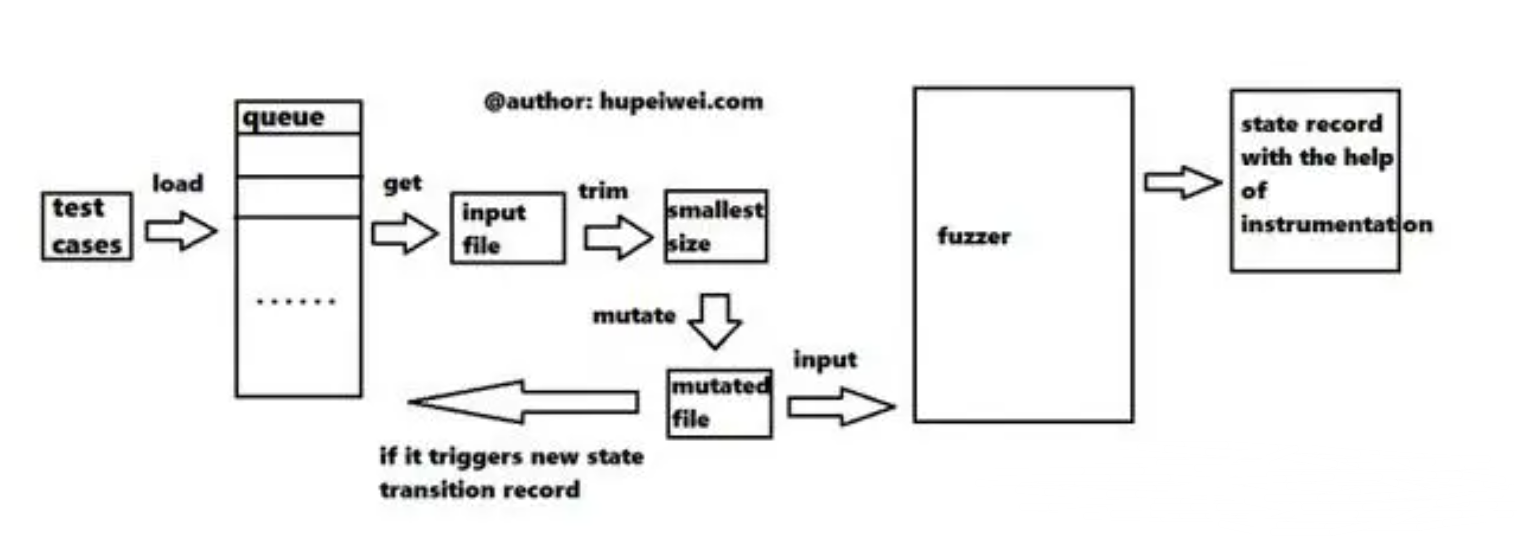
调试人员为程序提供一些输入,即最左侧的testcases,AFL加载后将其放入一个队列中。对于每一次迭代,AFL首先从队列中取出一个testcase,然后对它进行修剪,去除不必要的数据以提高运行效率;再然后对输入进行变异操作,变异的模式很多,可以产生很多新的testcase。对于这些新产生的输入,将它们送到目标程序运行,若能够产生新的执行路径或者导致程序崩溃,就把它再放到队列中。在整个过程中,程序崩溃会被记录下来,它可能代表一个潜藏的漏洞。
AFL和LibFuzzer的区别
LibFuzzer和AFL是目前最基本的两个模糊测试工具,而大部分的Fuzzer都是基于AFL和Libfuzzer进行进一步改进实现的,只要将这两个模糊测试工具弄明白,其它工具的安装和部署都是大同小异。
AFL和LibFuzzer的区别
- 集成方式:
- LibFuzzer: 通常与源代码直接集成,作为代码的一部分进行编译。它需要目标函数(即被测试的函数)的接口符合特定的格式(接受字节数组和长度作为参数)。
- AFL: 可以作为一个独立的工具运行,不需要对源代码进行修改。它通过插桩技术来监控程序的执行,以此来引导测试用例的生成。
- 测试用例生成:
- LibFuzzer: 使用基于覆盖率的指导来动态生成测试用例,旨在最大化代码覆盖率。
- AFL: 同样使用基于覆盖率的方法,但还结合了遗传算法来进化测试用例。
- 使用场景:
- LibFuzzer: 由于需要与源代码直接集成,因此更适合于对特定函数或模块进行深入的单元测试。
- AFL: 由于可以作为独立工具运行,因此更适合于对整个应用程序进行模糊测试,包括二进制文件。
根据不同的场景,我们可以从AFL和LibFuzzer中做出选择
AFL的安装
从 github项目主页 下载压缩包,解压后进入所在目录。
执行以下命令进行编译和安装:
1 | make |
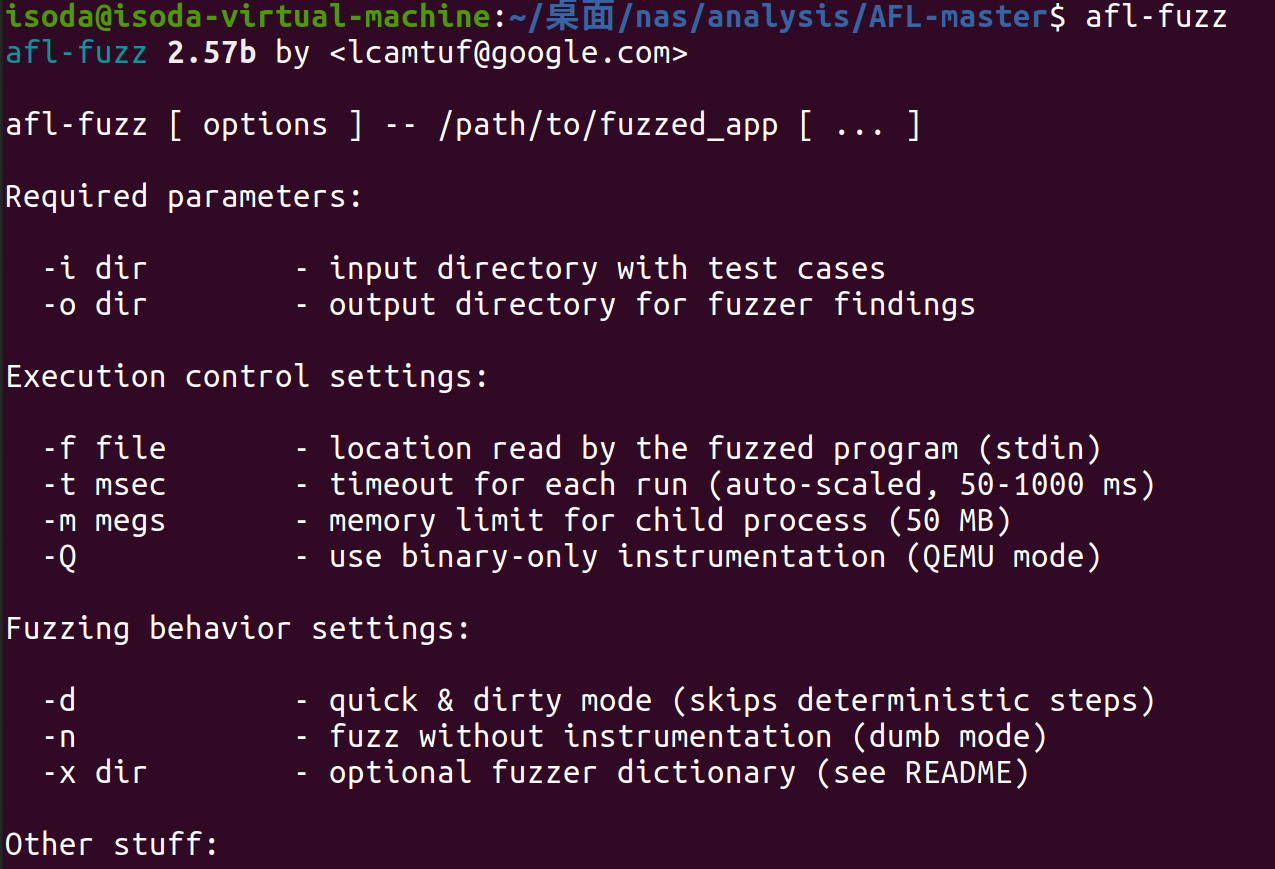
输入 afl-fuzz 测试是否编译成功
使用AFL进行模糊测试实战
前置准备
-
确定项目用什么语言编写
AFL主要用于C/C程序的测试,所以我们先要确定项目是否为C/C编写。(也有一些基于AFL的JAVA Fuzz程序如kelinci、java-afl等,但并不知道效果如何)
如果要批量使用AFL进行模糊测试,如何判断项目的语言:
- 项目提供了源代码:使用 github-linguist库 进行判断
- 项目仅提供二进制文件:
-
是否有示例程序、测试用例
-
如果目标有现成的示例程序,特别是一些开源的库,可以方便我们直接用示例程序调用该库,不用自己再写一个程序
-
如果目标已经提供测试用例,那后面构建语料库时也省事儿一点
-
-
项目规模
某些程序规模很大,会被分为好几个模块,为了提高Fuzz效率,在Fuzzing前,需要定义Fuzzing部分。这里推荐一下源码阅读工具Understand,它
treemap功能,可以直观地看到项目结构和规模。比如下面ImageMagick的源码中,灰框代表一个文件夹,蓝色方块代表了一个文件,其大小和颜色分别反映了行数和文件复杂度。
构建语料库
AFL需要一些初始输入数据(即种子文件)作为Fuzzing的起点,这些输入甚至可以是毫无意义的数据,AFL可以通过启发式算法自动确定文件格式结构。
尽管AFL如此强大,但如果要获得更快的Fuzzing速度,那么就有必要生成一个高质量的语料库,这一节就解决如何选择输入文件、从哪里寻找这些文件、如何精简找到的文件三个问题。
标准模式——有源码fuzz
编译插桩
首先我们可以自行用编写一个有漏洞的C语言程序 afl_test.c
1 |
|
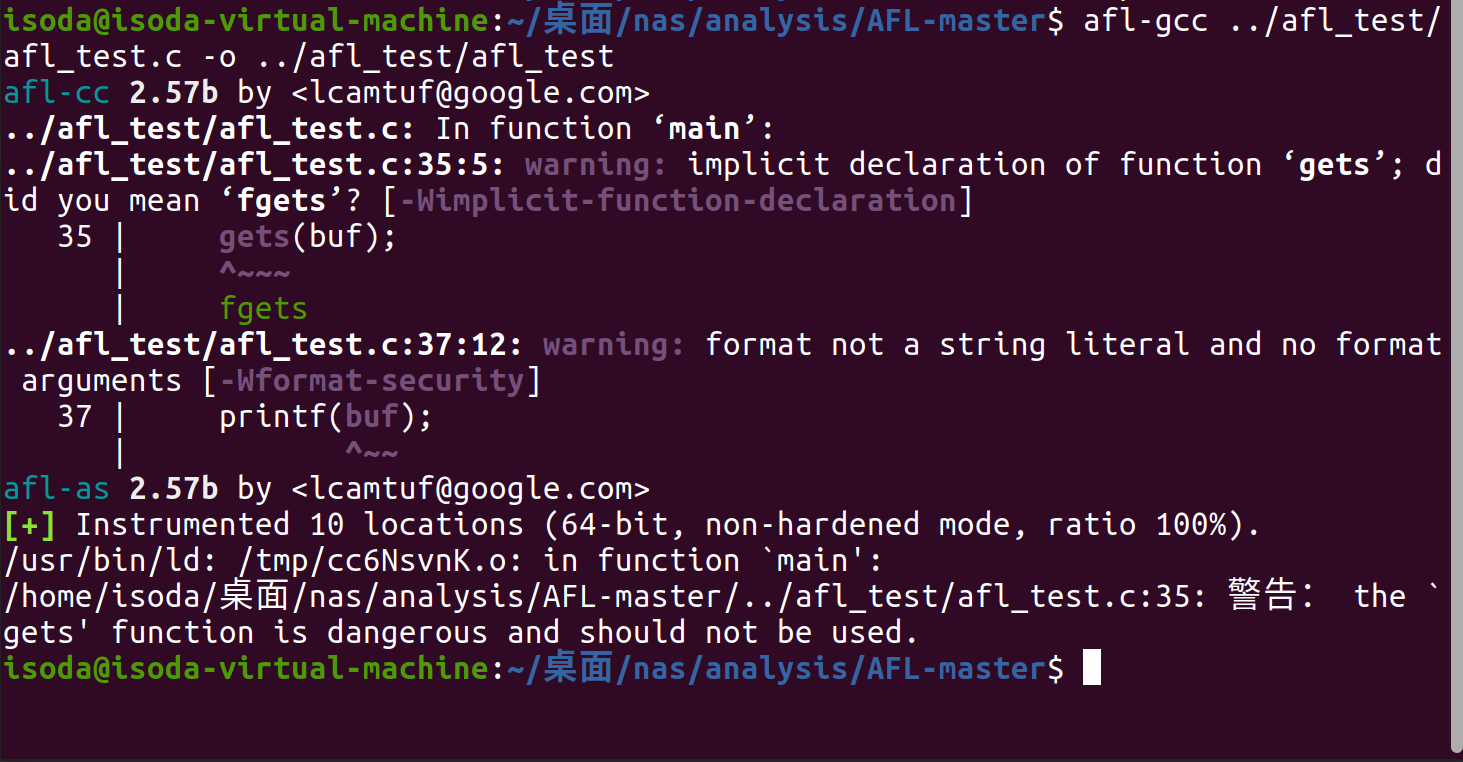
对该源文件进行编译插桩
1 | afl-gcc afl_test.c -o afl_test |
如果编译一个c的源码,使用afl-g。
现实情况下,我们往往需要对一整个项目而不是单个的C/C文件进行fuzz,所以需要指定afl-gcc/afl-g对整个项目进行编译插桩
命令的具体含义与作用可以参考文章xx的
linux下软件的发布与安装部分内容
1 | ./configure CC="afl-gcc" CXX="afl-g++" --disable-shared # 指定C和C++的编译器为afl所提供的编译插桩工具 |
编译后的结果如下图,可以看到对我们留下的漏洞产生了warning,不用理会
建立输入和输出文件夹
一般的程序接收的输入为标准输入流stdin类型或者文件类型
stdin指的是从标准输入流(stdin,标准输入设备)中获取输入数据。
stdin通常用于从终端(命令行)或其他程序中读取输入。这种方式可以让程序接受用户的交互式输入或从其他程序输出中获取数据,而无需直接依赖于文件或其他输入源。
对于我们这个文件afl_test.c,可以知道接收的输入类型为stdin标准输入流
建立两个文件夹:fuzz_in和fuzz_out,用来存放程序的输入和fuzz的输出结果。
1 | mkdir fuzz_in |
在fuzz_in文件夹下构建初始测试用例:
1 | cd fuzz_in |
在testcae文件中写入程序的输入数据,这里也可以随意输入一点文本,作为起始种子。(因为afl会根据初始种子自动变异生成更多的测试样例,所以初始种子可以随意一点)
1 | echo "asdsas" >> testcase |
afl-fuzz会将testcase文件中的内容作为输入,通过标准输入流(stdin)传递给目标程序。所以这里是基于stdin而并不是文件
使用 afl-fuzz 工具执行fuzz测试
针对程序不同的输入类型:
-
从stdin读取输入的目标程序,fuzz命令语法如下:
1
./afl-fuzz -i testcase_dir -o findings_dir /path/to/program […params…]
-i:指定测试用例所在的目录,表示从该目录中读取输入数据。-o:指定fuzz结果输出的目录/path/to/program:表示目标程序的路径[...params...]:表示其他可能的参数。
-
从文件读取输入的目标程序来说,语法如下:
1
./afl-fuzz -i testcase_dir -o findings_dir /path/to/program @@
使用如下命令执行fuzz:
1 | ./afl-fuzz -i fuzz_in -o fuzz_out ./easy_test |
经过一个半小时的fuzz,总共找到了4条执行路径(对应前面的程序代码),8个crash。
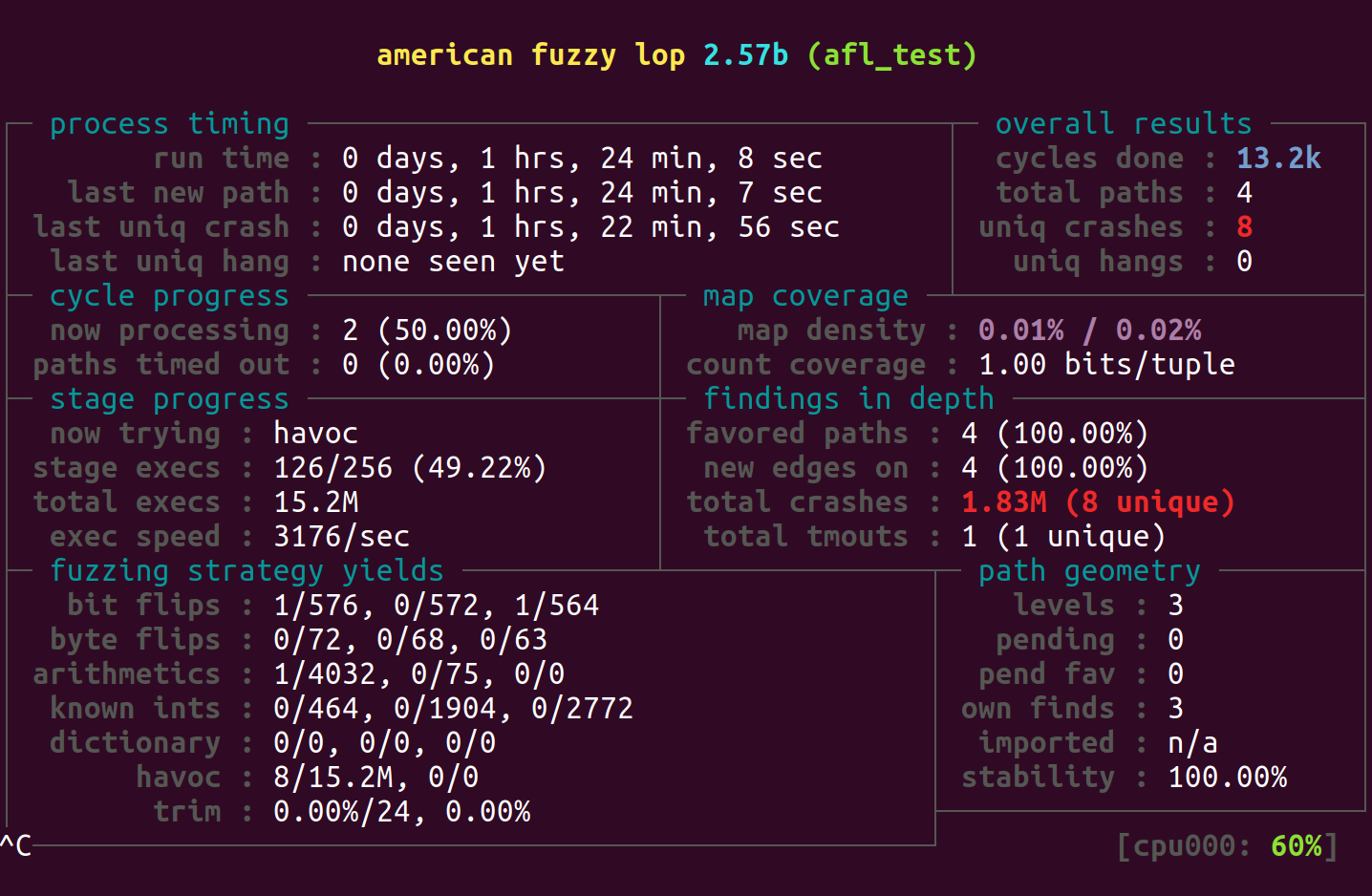
结束fuzz
afl-fuzz永远不会停止,所以何时停止测试很多时候就是依靠afl-fuzz提供的状态来决定的。具体的几种方式如下所示:
- 状态窗口的
cycles done变为绿色; afl-whatsup查看afl-fuzz状态;afl-stat得到类似于afl-whatsup的输出结果;- 定制
afl-whatsup->在所有代码外面加个循环就好; - 用
afl-plot绘制各种状态指标的直观变化趋势; pythia估算发现新crash和path概率。
结果分析
fuzz界面分析
根据上面的fuzz界面图:
-
process timing:
-
last new path: 表示自从最后一个新路径被发现以来经过的时间。这可以帮助你了解新路径发现的频率。如果这个字段产生了报错,如:
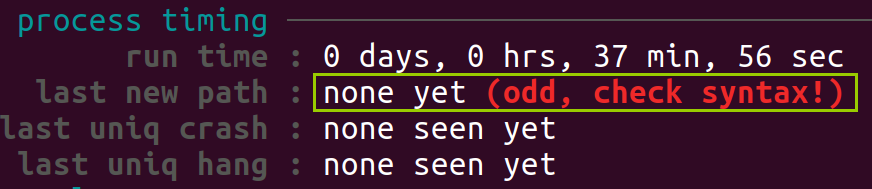
可能是因为:
- 语法错误:检查你的测试用例和目标程序,确保它们的语法正确。
- 测试用例不足:如果你提供的初始测试用例过于简单或不足以触发新的路径,AFL 可能无法有效地探索目标程序的状态空间。
- 代码覆盖率低:目标程序的某些部分可能难以触及,导致 AFL 无法发现新的路径。
- 目标程序简单:如果目标程序非常简单,可能只有很少的执行路径,因此 AFL 无法发现新的路径。
- 配置问题:检查 AFL 的配置设置,确保它们适合你的测试目标和环境。
接下来要及时修正,不然继续fuzz也是徒劳(因为路径是不会改变的),可以采取以下解决方案:
- 增加测试用例:提供更多或更复杂的初始测试用例,以帮助 AFL 探索新的路径。
- 调整 AFL 设置:调整 AFL 的参数和设置,例如增加变异率或改变变异策略,以尝试发现新的路径。
- 优化目标程序:如果可能,修改目标程序以增加可触及的代码路径。
- 增加测试时间:延长测试的时间,给 AFL 更多的机会发现新的路径。
- 检查目标程序:确保目标程序没有错误,且适合模糊测试。
-
last uniq crash: 表示自从最后一个独特崩溃被发现以来经过的时间。 -
last uniq hang: 表示自从最后一个独特挂起被发现以来经过的时间。
-
-
overall results:
-
cycles done: 表示 AFL 完成的模糊测试循环次数。每个循环包括一系列的变异测试用例。如果这个字段变绿就说明后面即使继续fuzz,出现crash的几率也很低了,可以选择在这个时候停止
-
total paths: 表示 AFL 发现的总路径数量。每个路径代表程序执行中的一个独特分支或状态。 -
unique crashes: 表示 AFL 发现的独特崩溃数量。这些崩溃可能是潜在漏洞的指示。 -
unique hangs: 表示 AFL 发现的独特挂起数量。挂起可能是由于程序陷入无限循环或其他无响应状态造成的。
-
cycles done:uniq crashes:代表的是crash的数量
-
cycle progress
-
map coverage
-
stage progress
包括正在测试的fuzzing策略、进度、目标的执行总次数、目标的执行速度。 执行速度可以直观地反映当前跑的快不快,如果速度过慢,我们可能需要进一步优化我们的Fuzzing。
-
findings in depth
-
fuzzing strategy yields
-
path geometry
fuzz_out分析
使用 tree 命令查看out文件夹的目录结构
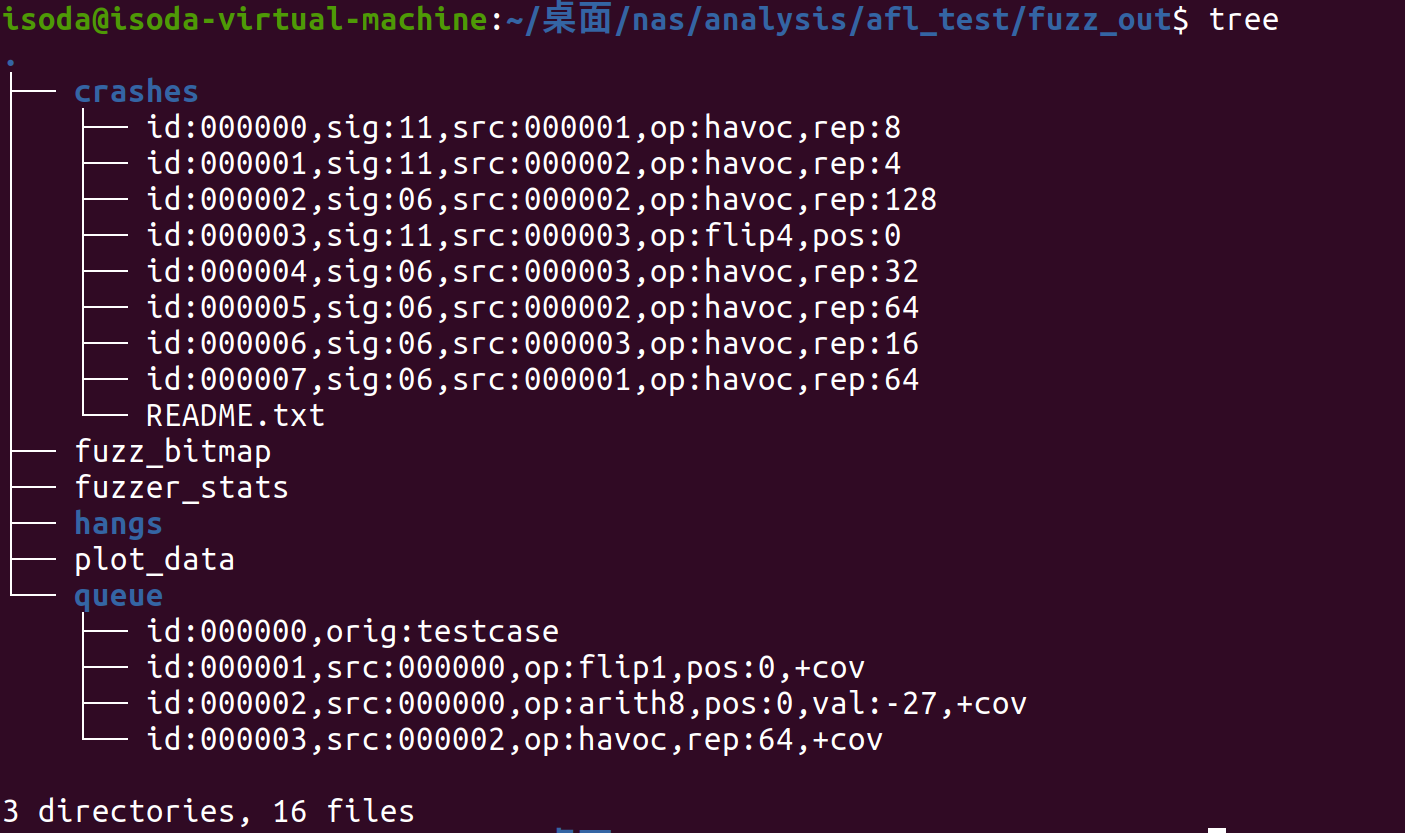
目录中文件的作用:
- queue/:存放所有具有独特执行路径的测试用例
- crashes/: 存放能触发待测程序崩溃的测试样本
- hangs/ :存发导致待测程序超时的测试样本
- fuzzer_stats - 文本文件,包含了fuzzer的实时统计信息,如执行速度、路径覆盖等度量指标。这个文件不断更新以反映当前的fuzzing状态。
- plot_data - 文本文件,包含了AFL执行过程中的统计数据。使用AFL的
afl-plot工具处理plot_data文件,可以生成fuzz过程的可视化图像。 - fuzz_bitmap - 这是用来记录路径覆盖率的位图(coverage bitmap),非人类可读。AFL使用这个位图来跟踪程序在处理不同输入时执行的不同分支,用来帮助AFL识别新的、唯一的代码路径,以便后续生成更具有探索性的测试样本。
查看 fuzz_out/crashes 文件夹,下面的十六进制文件即为产生崩溃的结果,
可以通过 xxd 命令查看对应测试用例的内容

可以看到产生crash的用例都符合栈溢出漏洞的情况
qemu模式——无源码黑盒测试
qemu模式为在没有源代码的情况下,直接对二进制程序进行fuzzing。注意此类方法准确度较低。
下载安装qemu
1 | cd qemu_mode |
当出现各种库的缺失报错,参考:深入分析 afl / qemu-mode(qemu模式) / afl-unicorn 编译及安装存在的问题以及相应的解决方案
然后修改 build_qemu_support.sh 文件
1 | QEMU_URL="http://download.qemu-project.org/qemu-${VERSION}.tar.xz" |
修改为
1 | QEMU_URL="http://download.qemu.org/qemu-${VERSION}.tar.xz" |
删除掉红框部分
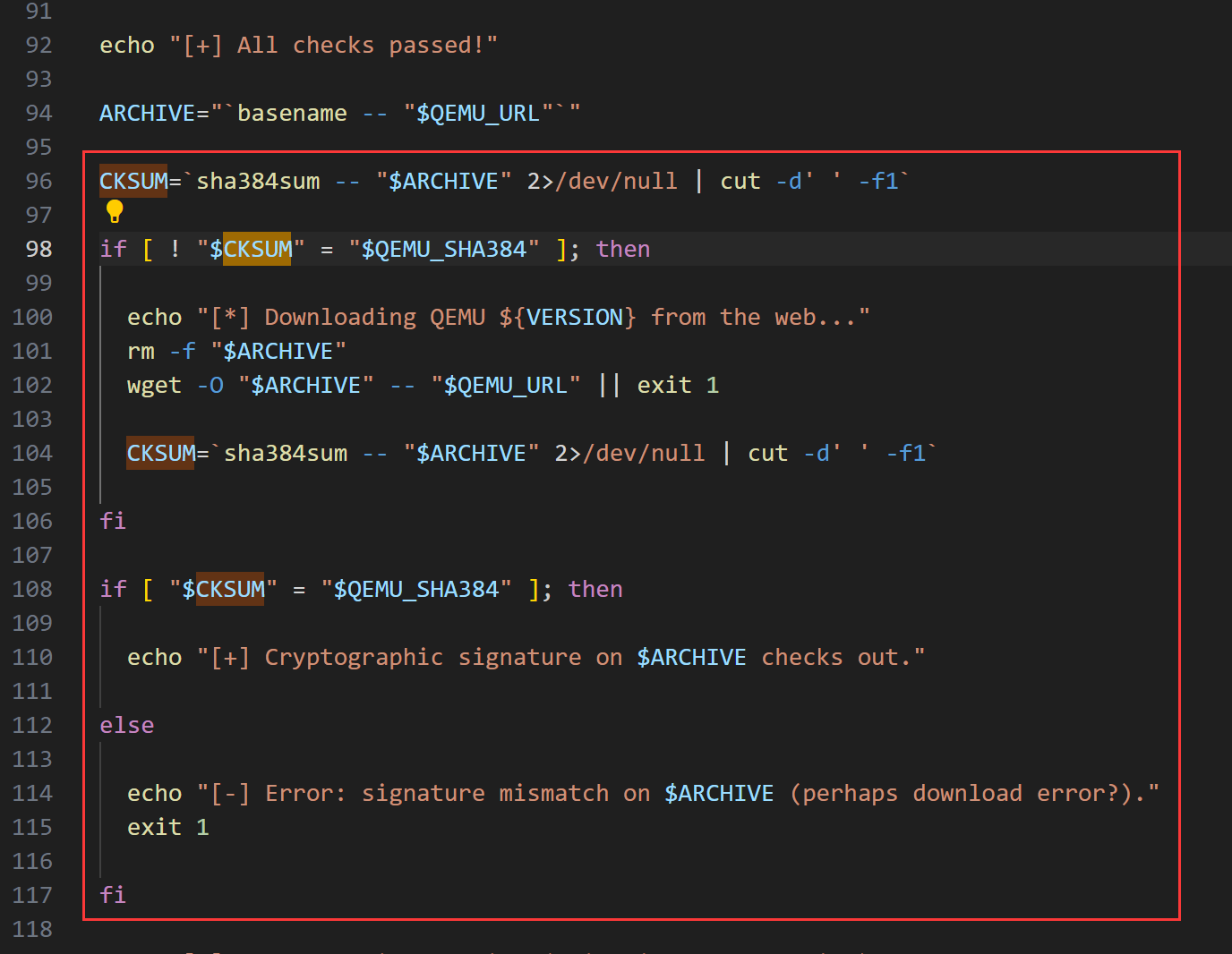
找到下面这部分
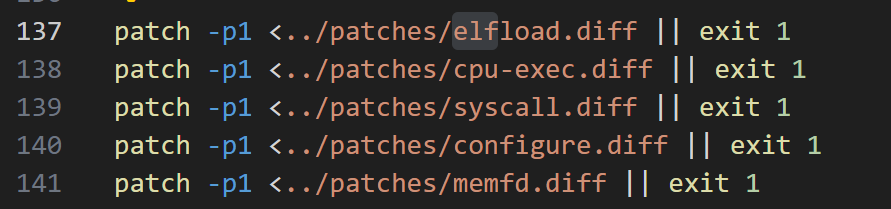
删除后三行,更换为:
1 | patch -p1 <../patches/syscall2.diff || exit 1 |
添加补丁文件 paches/syscall2.diff ,文件内容如下:
1 | --- qemu-2.10.0-clean/linux-user/syscall.c 2020-03-12 18:47:47.898592169 +0100 |
添加补丁文件 paches/memfd_create.diff ,文件内容如下:
1 | diff -ru qemu-2.10.0-clean/util/memfd.c qemu-2.10.0/util/memfd.c |
再运行 ./build_qemu_support.sh ,终于成功了
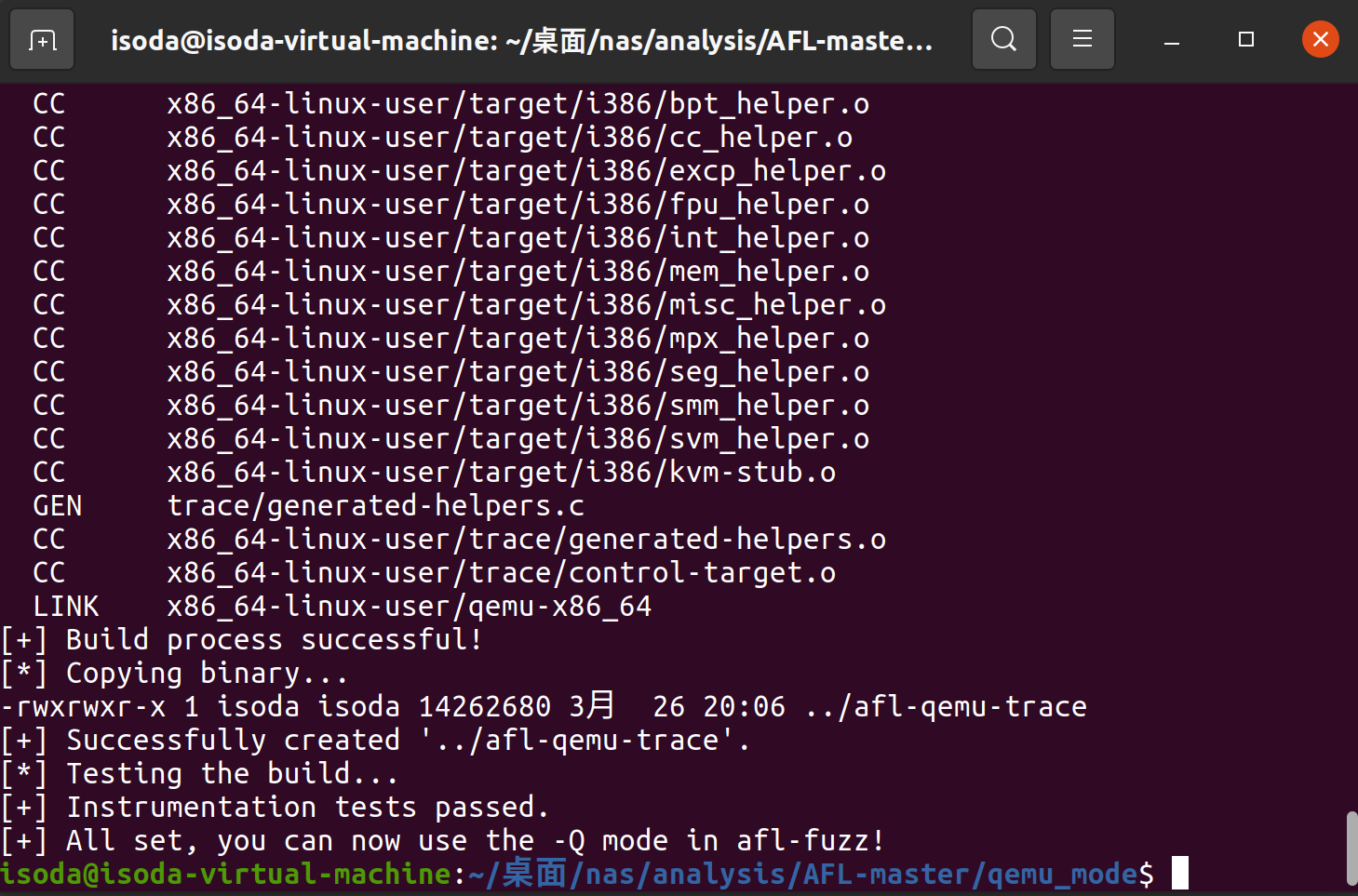
使用qemu模式fuzz
1 | ./afl-fuzz -i fuzz-in -o fuzz-out -Q ./mips-test |
和有源码fuzz的区别就是加上了一个参数 -Q
如果为文件输入记得在末尾加上 @@
报错问题
在执行 ./afl-fuzz -i fuzz_in -o fuzz_out ./easy_test 命令的时候,产生了如下报错:
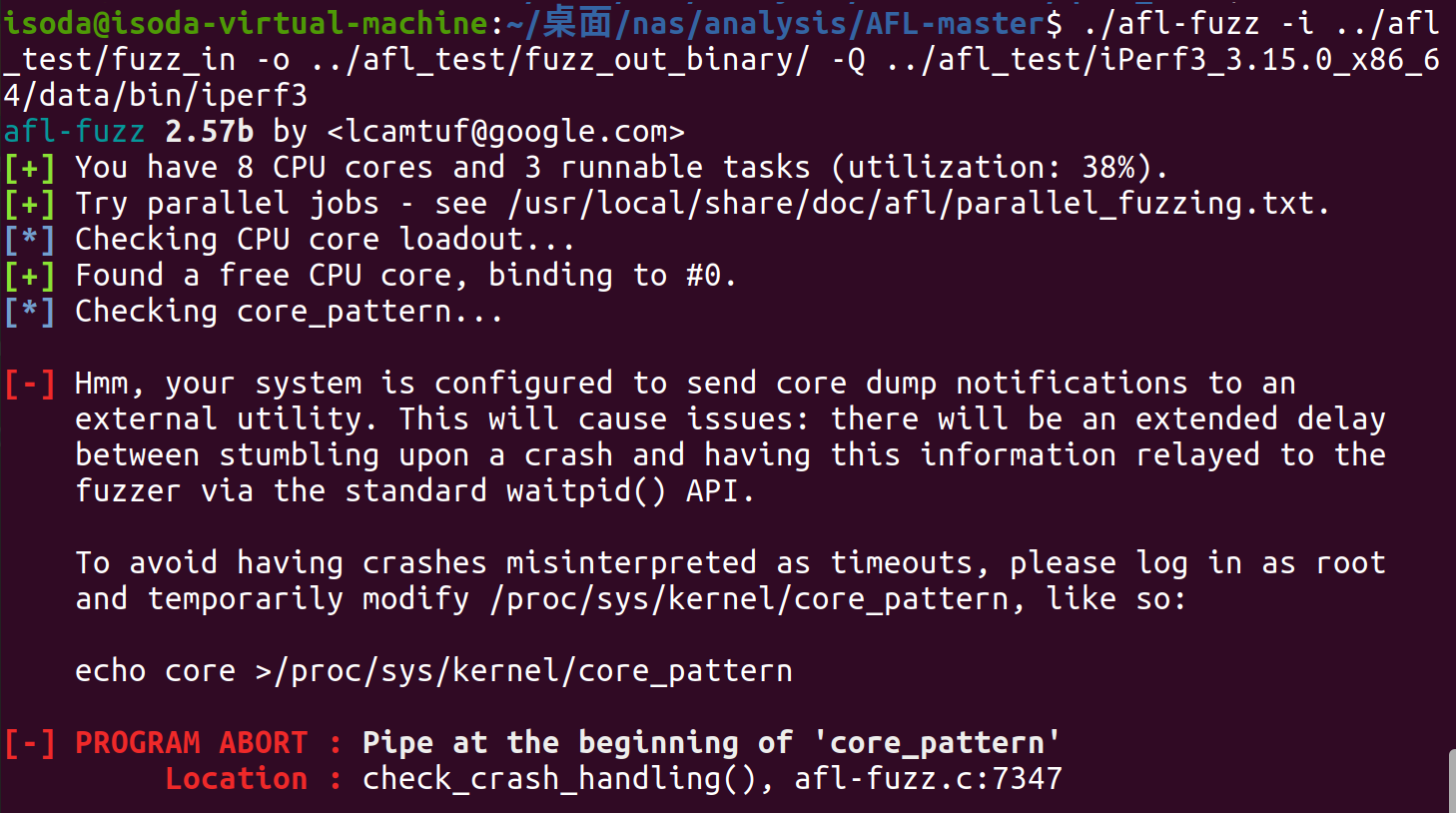
按照报错信息,输入 echo core >/proc/sys/kernel/core_pattern,提示权限不够的话可以输入以下代码:
1 | echo core | sudo tee /proc/sys/kernel/core_pattern |
这里是因为重定向操作符
>在执行前就已经获得了 sudo 权限,但是echo命令本身并没有获得 sudo 权限。解决方法是使用
tee命令,因为tee命令可以将输入内容写入文件,而且可以使用 sudo 权限执行。

参考文章
 wechat
wechat