『Python爬虫』单线程、多线程、多进程和异步协程爬虫
本文系统对比了单线程、多线程、多进程和异步协程四种 Python 爬虫实现方式,结合原理剖析、优缺点分析和完整代码 Demo,帮助你快速选择最适合的并发模型。
基本概念
并发爬虫基础
-
原理
并发爬虫是指能够同时发起多个请求、同时处理多个网页内容的爬虫程序,从而可以提高爬取效率和吞吐量。
将整个爬虫程序分为CPU操作和IO操作两部分。CPU首先开始执行task,在遇到IO操作时,CPU会切换到另一个Task开始执行,IO操作结束后,再通知CPU进行处理。由于IO操作读取内存、磁盘网络等不需要CPU的参与,两者可以同时进行,CPU可以释放出来执行其他Task实现加速。采用多线程并发操作执行程序可以大大降低运行时间,提高效率。

-
优点
- 速度快、效率高。减少了不必要的等待时间,使得整个程序运行速度大大加快。
- 安全性高。多线程可以采用Lock机制来控制全局共享变量,确保数据的正确性。
-
分类
- 多进程爬虫
- 多线程爬虫
- 异步协程爬虫
-
四种爬虫方式的对比
对比维度 🧵 单线程 🔀 多线程 🔁 多进程 ⚡ 异步协程 👷 并发方式 无 操作系统级线程(Thread) 操作系统级进程(Process) 事件循环驱动的协程 🔄 调度方式 顺序执行 OS 调度线程 OS 调度进程 程序内部调度(由事件循环协程调度) 🚀 并发能力 差 中 高(适合多核 CPU) 高(适合 I/O 密集) 🔧 执行效率 慢 一般(受 GIL 限制) 快(多个 CPU 核心并行) 非常快(任务切换开销小) 💾 资源消耗 极低 中(线程上下文 + 栈内存) 高(每个进程独立内存空间) 极低(不创建线程/进程,内存占用小) 💥 崩溃影响范围 整个程序 整个程序可能被一个线程拖崩 子进程崩溃不会影响主进程 某个协程异常一般不会导致全局崩溃 ⚠️ GIL 限制 有 有(无法利用多核并行执行 Python 代码) 无(每个进程有自己的解释器) 有(但 I/O 时主动让出控制权,影响小) 💬 编程复杂度 简单 中(需线程锁等) 中(需使用 Queue/Pipe 通信) 高(需理解 async/await、事件循环) 📈 适用任务类型 小规模爬取,学习入门 中等规模网页爬取,I/O 密集 CPU 密集型任务、大数据处理 大量网页爬取、高并发、长延迟 I/O 🧩 数据共享 全局变量 全局变量(需加锁,线程不安全) 不共享(通过 Queue 通信) 全局变量(单线程无冲突) 📉 启动/切换开销 无 线程切换开销中等 进程启动 & 切换开销大 极小,协程之间切换只需几百纳秒 🧪 调试难度 最简单 中(需注意线程安全) 中(注意进程间通信) 稍复杂(异步逻辑栈追踪难)
相关概念
Python多进程、多线程基础
进程是操作系统分配资源的最小单元,线程是操作系统调度的最小单元。每个进程在执行过程中拥有独立的内存单元,而一个进程的多个线程在执行过程中共享内存。
全局解释器锁 GIL
全局解释器锁 (Global Interpreter Lock,GIL)是 CPython 中为了保证线程安全而引入的一个机制:同一时刻 只允许一个线程执行 Python 字节码,即使你有多个线程,它们在任意时间点都只能一个一个地轮流执行 Python 代码。
- 优点:实现简单,不需要为每个对象加锁,提升了 CPython 的开发效率。
- 缺点:在 CPU 密集型任务中无法实现真正的多线程并行,多线程程序性能反而可能比单线程差。
四种爬虫类型
单线程爬虫
-
原理
单线程爬虫是最基本的爬虫类型,通常一次只处理一个请求和响应。采用requests库发送get请求,获取响应text文本,再使用beautifulsoup库、正则表达式、xpath对网页文本进行解析以得到我们所需数据,之后再对数据进行其他处理。
-
流程
1
发送请求 → 等待服务器响应 → 解析响应 → 再发送下一个请求
-
特点
- 优点:适用于简单的小规模抓取任务。
- 缺点:由于其请求是串行的,速度较慢,容易受到网络延迟的影响。且大量时间被浪费在等待响应上(IO阻塞)
-
基本代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import requests
from bs4 import BeautifulSoup
import csv
def fetch(url):
response = requests.get(url)
return response.text
def parse(html):
soup = BeautifulSoup(html, 'html.parser')
quotes = soup.select('.quote')
results = []
for q in quotes:
text = q.select_one('.text').get_text(strip=True)
author = q.select_one('.author').get_text(strip=True)
results.append((text, author))
return results
def save_to_csv(data):
with open('quotes_single.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Quote', 'Author'])
writer.writerows(data)
if __name__ == '__main__':
url = 'http://quotes.toscrape.com/page/1/'
html = fetch(url)
quotes = parse(html)
save_to_csv(quotes)
多进程
-
原理
多进程爬虫使用多个进程来同时运行,每个进程独立工作,不受 GIL 限制,可以充分利用多核 CPU,适用于 CPU 密集型任务(如图像处理等)。Python 中可以使用
multiprocessing库实现。 -
特点
1)优点
- 不受 GIL 限制,适合 CPU 密集型任务
- 每个进程有独立的内存空间,避免了线程的共享内存问题
2)缺点
- 启动进程开销较大
- 进程间通信较为复杂
- 内存占用较高
-
基本代码
使用
multiprocessing库提供的进程池 Pool 来管理多进程任务。池子里进程的数量,一般建议为CPU的核数,这是因为一个进程需要一个核,你设多了也没用。我们使用
map方法创建了多进程任务,你还可以使用apply_async方法添加多进程任务。任务创建好后,任务的开始和结束都由进程池来管理,你不需要进行任何操作。这样我们一次就有3个进程同时在运行了,一次可以同时处理3个请求。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import requests
from bs4 import BeautifulSoup
import csv
from multiprocessing import Pool
def fetch_and_parse(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3883.400 QQBrowser/10.8.4559.400',
}
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
quotes = soup.select('.quote')
return [(q.select_one('.text').get_text(strip=True),
q.select_one('.author').get_text(strip=True)) for q in quotes]
def save_to_csv(data):
with open('quotes_process.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Quote', 'Author'])
writer.writerows(data)
if __name__ == '__main__':
base_url = 'http://quotes.toscrape.com/page/{}/'
urls = [base_url.format(i) for i in range(1, 4)]
with Pool(processes=3) as pool:
results = pool.map(fetch_and_parse, urls)
flat_results = [item for sublist in results for item in sublist]
save_to_csv(flat_results)
多线程
-
原理
多线程爬虫是通过多线程同时处理多个请求来加速数据抓取。每个线程负责一个单独的任务(如抓取一个页面),可以在一定程度上提高爬取速度。
-
特点
1)优点
- 提高爬取效率
- 比单线程爬虫性能更好
2)缺点
- 因为存在全局解释器锁(GIL)的问题,Python 中多线程无法完全并行处理 CPU 密集型任务,但对 I/O 密集型任务(如爬取网页)效果很好
- 线程切换带来的额外开销
- 对系统资源(如内存)消耗较大
-
基本代码
通过 threading 库实现多线程爬虫
同时引入线程池(ThreadPoolExecutor) + 任务队列机制(Queue)
- 线程池:尽管在使用多线程进行爬虫时可以提高程序运行效率,但是线程的创建和销毁都会消耗资源,过多的创建线程会导致线程浪费,增加运行成本。引入线程池对线程进行管理,当我们需要调用线程时从线程池中获取,用完之后再归还入池中,实现线程的循环使用,大大降低运行成本。
- 任务队列机制(PCS模式):采用生产者-消费者模式(PCS)进行改进,引入队列。创建线程传入
url_queue队列执行生产者方法得到html_queue队列,消费者方法依次从html_queue队列中获取数据执行解析方法,得到输出数据。直到两个队列为空时,结束线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56import queue
import random
import time
from concurrent.futures import ThreadPoolExecutor
import threading
# 假设 blog_spider 模块定义了爬取与解析逻辑
import blog_spider
# 生产者:负责抓取网页
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while not url_queue.empty():
try:
u = url_queue.get(timeout=1)
html = blog_spider.craw(u)
html_queue.put(html)
print(threading.current_thread().name, f"craw {u}", 'url_queue.qsize=', url_queue.qsize())
time.sleep(random.uniform(1, 2))
except queue.Empty:
break
# 消费者:负责解析网页并写入文件
def do_parse(html_queue: queue.Queue, fout_lock: threading.Lock, fout):
while True:
try:
h = html_queue.get(timeout=3)
results = blog_spider.parse(h)
with fout_lock:
for result in results:
fout.write(str(result) + '\n')
print(threading.current_thread().name, f"results.size={len(results)}", 'html_queue.qsize=', html_queue.qsize())
time.sleep(random.uniform(1, 2))
except queue.Empty:
break
if __name__ == "__main__":
url_queue = queue.Queue()
html_queue = queue.Queue()
for u in blog_spider.urls:
url_queue.put(u)
fout = open('results.txt', 'w', encoding='utf-8')
fout_lock = threading.Lock()
# 使用线程池管理线程
with ThreadPoolExecutor(max_workers=5) as pool:
# 提交3个爬虫线程任务
for _ in range(3):
pool.submit(do_craw, url_queue, html_queue)
# 提交2个解析线程任务
for _ in range(2):
pool.submit(do_parse, html_queue, fout_lock, fout)
fout.close()
print("✅ 所有任务完成!结果已写入 results.txt")
异步协程爬虫
-
原理
异步协程爬虫不是像线程那样“并行运行”,而是利用事件循环调度多个任务,遇到 I/O 阻塞就让出控制权,执行其他任务,从而实现伪并发。当协程执行到耗时操作(如发 HTTP 请求)时:①协程“挂起”并交出控制权(
await)。②事件循环注册该任务。③当响应返回,事件循环重新调度协程继续执行。-
协程:是一种比线程更轻量级的并发编程方式,不依赖操作系统线程,由程序语言本身调度和切换(所以开销小,切换快,适合高并发场景)。在 Python 中,协程是使用
async def定义的函数,遇到await时可以暂停当前函数的执行,交出控制权,让事件循环调度其他协程执行。 -
事件循环机制:将所有任务注册到事件循环中,当遇到阻塞(如
await session.get())时让出 CPU 控制权,等待资源(如响应数据)准备好后继续执行,利用 CPU 时间切换不同任务,实现“看起来是并发”的效果(实为非阻塞串行)
-
-
特点
1)优点
- 协程切换开销小,切换速度快(没有线程/进程上下文切换的代价,CPU占用非常低)
- 内存开销低(不需要为每个任务开线程或进程)
- 高并发能力,适合IO密集型任务
2)缺点
- 不适用于CPU密集型任务,如图片处理、加密计算中协程反而会阻塞整个事件循环
-
基本代码
通过
asyncio + aiohttp库实现异步协程爬虫asyncio实现事件循环管理器 + 协程调度器aiohttp实现异步HTTP客户端(异步发送 HTTP 请求,获取响应数据)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73import aiohttp
import asyncio
from retrying import retry
from bs4 import BeautifulSoup
import pymongo
import random
# MongoDB连接
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["ecommerce_db"]
collection = db["products"]
# URL列表
urls = ['https://example.com/product/1', 'https://example.com/product/2', 'https://example.com/product/3']
# 请求头设置
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
# 代理池
class ProxyPool:
def __init__(self):
self.proxies = ['http://proxy1:port', 'http://proxy2:port', 'http://proxy3:port']
def get_proxy(self):
return random.choice(self.proxies)
proxy_pool = ProxyPool()
# 重试策略
async def fetch_url(session, url):
try:
proxy = proxy_pool.get_proxy() # 从代理池获取代理
async with session.get(url, headers=headers, proxy=proxy) as response:
if response.status == 200:
return await response.text()
else:
raise Exception(f"Error fetching {url}, status code {response.status}")
except Exception as e:
print(f"Error fetching {url}: {e}")
raise
# 解析网站文本
def parse_html(html):
soup = BeautifulSoup(html, 'html.parser')
product = {
'name': soup.find('h1', {'class': 'product-name'}).text.strip(),
'price': soup.find('span', {'class': 'product-price'}).text.strip(),
'url': soup.find('link', {'rel': 'canonical'})['href']
}
return product
# 异步获取所有URL
async def fetch_all(urls):
async with aiohttp.ClientSession() as session:
tasks = [fetch_url(session, url) for url in urls]
htmls = await asyncio.gather(*tasks)
products = [parse_html(html) for html in htmls]
store_data(products)
# 数据存储
def store_data(data):
try:
collection.insert_many(data)
print(f"Stored {len(data)} items.")
except Exception as e:
print(f"Error storing data: {e}")
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(fetch_all(urls))
分布式爬虫
-
原理
分布式爬虫(Distributed Crawler)是指将爬虫任务分布到多个节点或机器上并发执行的爬虫架构。相比于单机爬虫,分布式爬虫具有更高的爬取效率,能够应对海量网页的数据抓取需求。
-
分布式爬虫系统构成
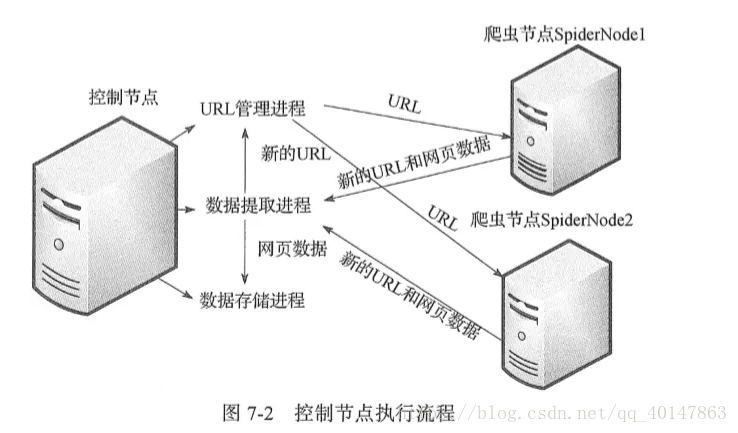
整个分布式爬虫系统由两部分组成:master 控制节点和 slave 爬虫节点
- master 控制节点负责:slave节点任务调度、url管理、结果处理
- slave 爬虫节点负责:本节点爬虫调度、HTML下载管理、HTML内容解析管理
系统工作流程:
master将任务(未爬取的url)分发下去,slave通过master的URL管理器领取任务(url)并独自完成对应任务(url)的HTML内容下载、内容解析,解析出来的内容包含目标数据和新的url,这个工作完成后slave将结果(目标数据+新url)提交给master的数据提取进程(属于master的结果处理),该进程完成两个任务:提取出新的url交于url管理器、提取目标数据交于数据存储进程,master的url管理进程收到url后进行验证(是否已爬取过)并处理(未爬取的添加进待爬url集合,爬过的添加进已爬url集合),然后slave循环从url管理器获取任务、执行任务、提交结果
-
核心架构
-
任务调度器:统一管理所有待爬 URL 的任务队列,实现任务分发、调度、去重。
Scrapy-Redis 使用 Redis 的 List 数据结构作为请求队列,所有的爬虫实例从同一个 Redis 队列中获取任务,执行爬取任务同时将响应结果放回 Redis中。
由于 Redis 支持高并发读写操作,这种机制能够有效地支持大量爬虫实例的任务分配。
-
下载器:将调度器提供的 URL 发起 HTTP 请求,并获取响应内容。
Scrapy 自带下载器支持中间件、代理、重试等机制。
-
解析器:解析网页 HTML,提取目标内容。
提取目标内容(如新闻标题、正文、时间),并提取下一批 URL(如分页或详情页)。
-
去重模块:防止抓取相同页面。
Redis中使用 Set 数据结构存储 URL 的哈希值,每次抓取一个 URL 时,先检查 Redis Set 中是否已经存在该 URL 的哈希值,如果存在则跳过;否则,将其添加到 Set 中,并进行爬取。
-
数据存储:将抓取的数据存入数据库或文件中,供后续使用。
爬取的数据可以存储在 Redis 中,或者通过 Scrapy 的管道将数据存储到其他数据库中。通过 Redis 的 Pub/Sub 功能,可以实现实时的数据监控和分发。
-
-
应用场景
-
基本代码
利用 Python 中的 Scrapy 框架和分布式任务队列来构建一个高效的分布式爬虫系统。
爬虫框架
主要包括scrapy和selenium,具体使用方法待补充
scrapy

scrapy架构组件构成:
- 引擎(Scrapy Engine):用来处理整个系统的数据流处理,触发事务(框架核心)。
-
调度器(Scheduler):用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。可以想象成一个 URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址。
-
下载器(Downloader):用于下载网页内容,并将网页内容返回给蜘蛛。Scrapy 下载器是建立在 Twisted 这个高效的异步模型上的。
-
爬虫(Spiders):爬虫是主要执行任务的部分,用于从特定的网页中提取所需的信息(即所谓的实体 Item)。用户也可以从中提取出链接,让 Scrapy 继续抓取下一个页面。
-
项目管道(Pipeline):负责处理爬虫从网页中抽取的实体,主要功能包括持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定顺序处理数据。
-
下载器中间件(Downloader Middlewares):位于 Scrapy 引擎和下载器之间的框架,主要用于处理 Scrapy 引擎与下载器之间的请求及响应。
-
爬虫中间件(Spider Middlewares):介于 Scrapy 引擎和爬虫之间的框架,主要负责处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middlewares):介于 Scrapy 引擎和调度器之间的中间件,用于处理从 Scrapy 引擎发送到调度器的请求和响应。
参考文章
 wechat
wechat