『大模型』本地部署chatglm3-6b
motivation
ChatGLM3-6B发布于2023年10月27日,是目前中文能力排名最高的开源LLM模型。对应项目的github地址:https://github.com/THUDM/ChatGLM3
实验室项目中需要本地部署大模型用于新闻文本摘要任务,因为预测速度的要求及硬件条件的限制,比较后选择该模型的6B版本。
本文为在linux环境下的chatglm3-6b的本地部署工程记录。
环境配置
CUDA与CUDNN
深度学习任务中,当使用GPU进行训练的时候,需要安装英伟达提供的驱动和显卡对应的cuda、cudnn。
什么是cuda和cudnn?
- CUDA(ComputeUnified Device Architecture):是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
- CUDNN:是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、torch
需要注意的是,cuda、cudnn和我们常用的深度学习框架(如tensorflow-gpu、torch-gpu)之间的版本存在对应关系,如果配置错误则代码不能运行。
我们首先查看服务器上的显卡相关信息,在命令行输入:
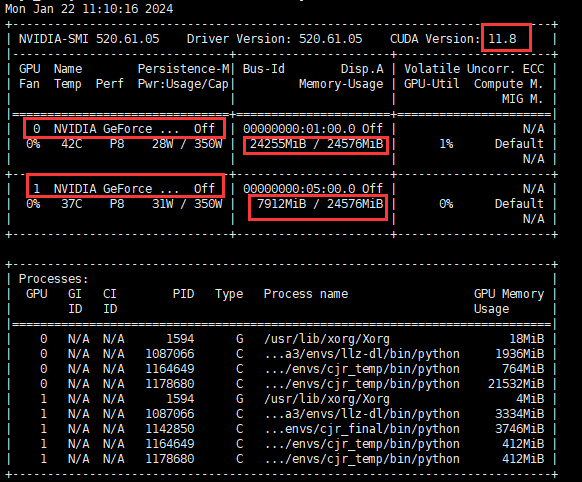
1 | nvidia-smi |
可以看到显卡支持的最高CUDA版本为11.8(注意这里是显卡支持的最高CUDA版本,而并不是目前系统安装的CUDA版本!)
同时可以看到这台服务器上装载了两个显存大小都为24G的GPU 0和1,其中GPU 0的显存几乎已经完全占满。
输入以下命令,查看是否已经安装了cuda:
1 | nvcc -V |
如果出现 Command 'nvcc' not found, but can be installed with: 的输出,说明该服务器的系统并没有安装cuda

可以看到我这台服务器上面已经安装了cuda,版本为11.8,所以并不需要进行cuda和cudnn的安装
如果你和我一样已经安装了cuda和cudnn,请跳转到下一部分,进行相对应torch-gpu的安装
cuda和cudnn的安装
这一部分我并没有进行,考虑后续有没有机会补上。
首先要创建一个Python ≥ 3.10的虚拟环境(chatglm3-6b要求)。
要注意虚拟环境中的cuda和系统中的cuda的区别,我这里的cuda就是直接安装在系统中,所有的虚拟环境都可以使用系统中安装的cuda
在虚拟环境中安装并使用其他版本的cuda,参考:https://blog.csdn.net/2301_80501457/article/details/134191613
要注意:如果你的cuda是直接安装在虚拟环境中,并非直接安装在系统中。是无法使用ncvv -V命令验证是否安装成功的,ncvv -V是通过系统变量来直接查询,而安装在虚拟环境中并没有直接建立系统变量。验证方法可以见上面链接的最后一部分。
pytorch-gpu的安装
pytorch-gpu的版本同样必须依赖于CUDA的版本。
注意,conda install pytorch 命令安装的是torch CPU版本,但是我们要使用GPU进行训练
在pytorch官网上获取cuda11.8对应版本torch的安装命令
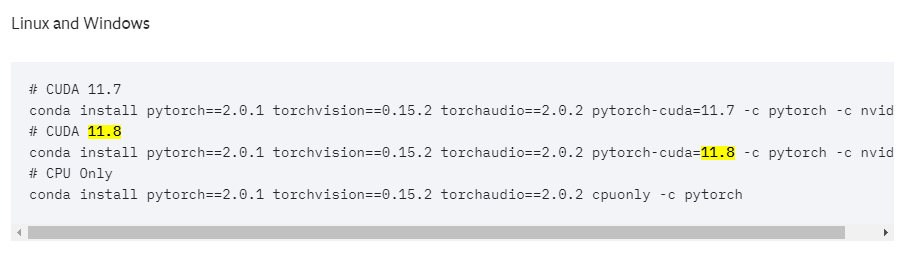
复制对应的命令,执行安装
安装完成后编写程序如下:
1 | import torch # 如果pytorch安装成功即可导入 |
运行结果如下:

已经配置成功
安装剩余依赖
clone下来ChatGLM3项目
1 | git clone https://github.com/THUDM/ChatGLM3.git |
超时的话挂梯子设置代理,使用服务器没办法挂梯子的话直接在github下载zip上传到服务器上
由于已经安装了torch,所以我们要删掉项目目录下requirements.txt中的 torch>=2.1.0 一行
并使用 pip 安装剩余的依赖
1 | pip install -r requirements.txt |
这里一定要删除torch相关依赖行!!不然会自动给你下载冲突的torch版本,后续项目报错
下载ChatGLM3-6b模型及参数
方法1:从 Hugging Face Hub 下载模型
首先需要安装Git LFS,否则会出现模型中的大型文件下载不完整的情况。
输入以下命令
1 | git lfs install |
若显示 Git LFS initialized ,说明已经安装。
可以使用git进行克隆,运行:
1 | git clone https://huggingface.co/THUDM/chatglm3-6b |
如果下载比较慢或者超时,可以直接去官网下载模型再上传到服务器
方法2:从 ModelScope 下载模型(推荐)
同样也可以在国内魔搭社区下载,一般不会超时
1 | git lfs install |
注意,这里一定要
git lfs install,虽然我查了这个命令仅仅只是用于验证是否安装了git lfs,但是我第一次从魔搭git clone的时候,没有使用这个命令产生了大文件下载不完整的情况,加上后没有再出现这样的问题,所以建议还是加上吧。
代码调用模型进行预测
下载完成模型及参数文件后,我们将所有的文件放在一个文件夹chatglm3-6b里,然后将其放在项目文件夹ChatGLM3-main下

然后我们可以在项目主目录下创建test.py文件,通过如下代码调用 ChatGLM 模型来生成对话:
1 | from transformers import AutoTokenizer, AutoModel |
这里使用"chatglm3-6b/"就是加载了该文件夹下的本地模型及文件
在命令行输入,执行代码
1 | CUDA_VISIBLE_DEVICES=1 python test.py |
注意,这里的
CUDA_VISIBLE_DEVICES=1的作用是指定使用 GPU 1 来跑模型,因为我们前面已经通过nvidia-smi知道 GPU 0 的显存已经基本占满了cuda指定GPU、设置多GPU的方法:https://blog.csdn.net/OneQuestionADay/article/details/111691486
构建网页版demo
官方教程:https://github.com/THUDM/ChatGLM3/blob/main/composite_demo/README.md
安装 Jupyter 内核:
1 | ipython kernel install --name chatglm3-demo --user |
因为我们是本地下载的模型,所以需要先设置环境变量 MODEL_PATH 来指定从本地加载模型
直接在终端中输入如下命令即可
1 | export MODEL_PATH=//home/xjb/event/ChatGLM3-main/chatglm3-6b |
然后输入命令:
1 | CUDA_VISIBLE_DEVICES=1 streamlit run composite_demo/main.py |
注意这里一样要在命令的前面加上
CUDA_VISIBLE_DEVICES=1来设置使用的GPU
运行结果:

如果你部署在了服务器上而不是本机,访问对应的network url既可使用网页demo
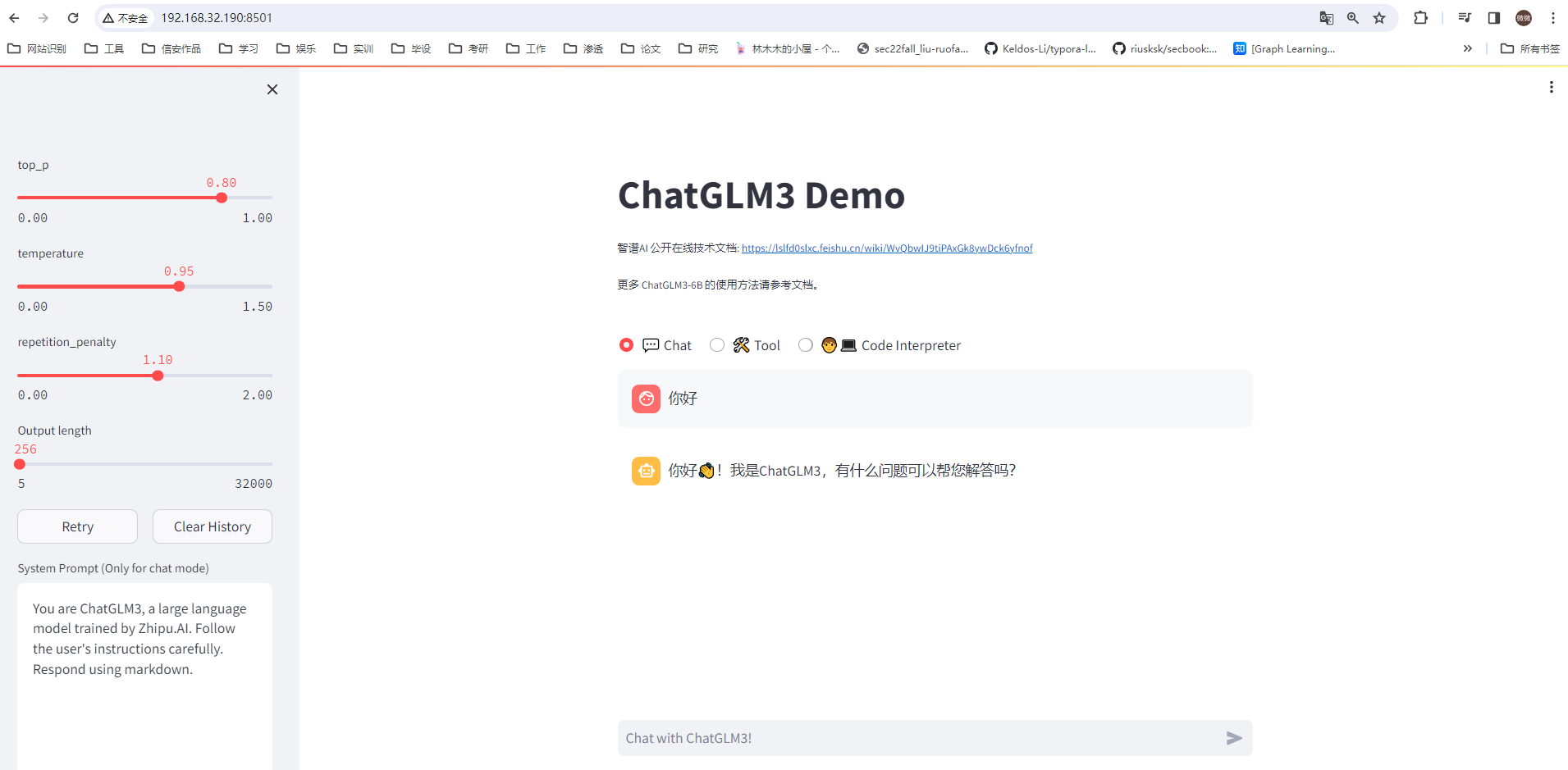
现在你就拥有一个属于自己的本地大模型啦,因为该模型较轻量级,预测的速度还是比较快的,在未经过微调的情况下我直接将其用于新闻文本的摘要任务,大概1-2秒可以生成一篇文本的摘要,效果也比较不错,但是偶尔会出现中英文乱码的情况。
你也可以对其进行进一步的领域微调,使其更适合你的任务。
参考文章
 wechat
wechat