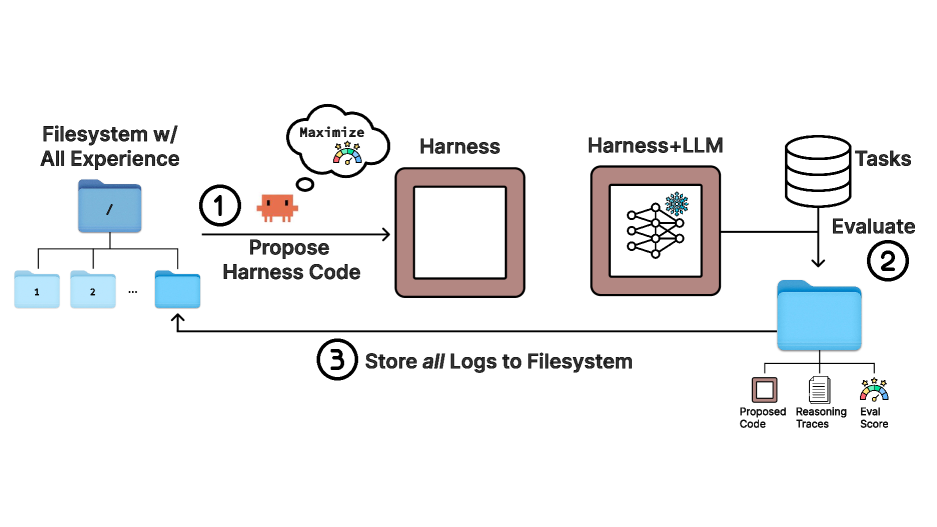
『工程记录』修改bert-extractive-summarizer项目用于中文文本摘要任务
motivation
本文为bert-extractive-summarizer项目改中文模型记录
该模型的原理在于:通过bert生成句子嵌入,对句子嵌入做聚类,找到最接近聚类质心的句子,同时使用neuralcoref库实现共指消解功能(比较符合目前的业务,项目数据集中的政治新闻大多系外媒台媒文章,不像国内的文章那样规范,行文比较随意,同时因为外文翻译为中文存在一些语句翻译质量低,所以存在很多的指代问题)
发现原始模型做的是英文的摘要生成,要进行中文摘要需要将其修改成中文的Bert模型和分词器,参考作者给出的中文模型文档和github下的issue完成了中文摘要的提取。
环境搭建
spacy + neuralcoref 搭建共指消解环境
指代消解任务通过spacy + uralcoref实现。spacy是一个NLP领域的文本预处理Python库,包括分词、词性标注、依存分析等多个nlp基础任务的实现,neuralcoref相当于一个插件,在spacy框架下实现指代消解。
我在初次安装过程中出现了Spacy和neuralcoref的版本适配问题,安装很多版本都不能顺利运行,各种error。最终找到一个匹配的安装方式,按照下面的流程来进行安装的话应该不会出现兼容性的问题。
如果你是英文任务的话,推荐:spacy 2.1.0 + neuralcoref 4.0 + en_core_web_sm-2.1.0
但是这一套对中文模型版本并不适用, neuralcoref并不支持中文共指消解。所以对中文任务而言,如果要使用这里的共指消解,需要使用其他的支持中文的共指消解工具。
因此我们后面的中文摘要生成部分并没有使用共指消解,后续有机会可以尝试加上
我们先pip install spacy==2.1.0,前面提到neuralcoref相当于spaCy的一个插件,所以先安装neuralcoref会自动帮我们安装 spacy,可能会产生版本冲突。
接下来安装spacy 2.1.0版本库上的 transformer-based pipelines 的预训练模型 en_core_web_sm-2.1.0,注意这里的版本一定要和前面的spacy一样,产生报错建议手动安装
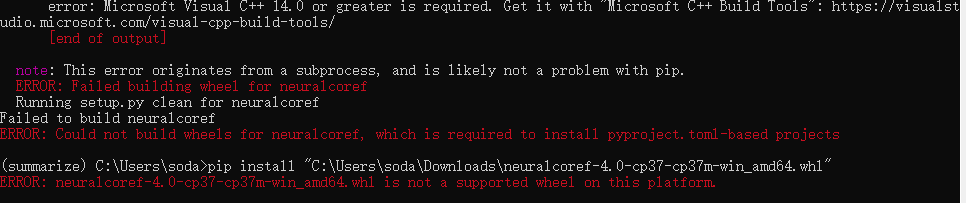
安装完spacy后安装neuralcoref,建议这里去pypi上找到对应的 neuralcoref包 下载到本地后手动安装,不然可能会产生下面的报错:
搭建 bert-extractive-summarizer 环境
首先从github上clone该项目
然后运行一个小demo
1 | from summarizer import Summarizer |
下载好相应的依赖后发现出现报错:

这里的报错原因在于:代码试图从Hugging Face模型存储库(https://huggingface.co)下载模型文件,但由于网站不稳定等原因无法连接到该服务器。
在使用Hugging Face Transformers库时(很多需要用到某些模型的机器学习库都是这样),如果你指定的模型没有在本地缓存中找到,库会尝试从Hugging Face模型存储库下载所需的模型文件,以便进行后续的模型初始化和使用。这是因为模型文件通常比较大,不方便直接包含在库中,因此在需要时会动态下载。
因此这里我们选择手动下载模型
手动下载中文模型
Hugging Face Transformers库所使用的默认bert模型 bert-large-uncased 只可以用于英文语料,如果我们要将该项目应用在中文的摘要任务上需要稍作修改,使用一个中文的bert模型和一个中文的分词器。
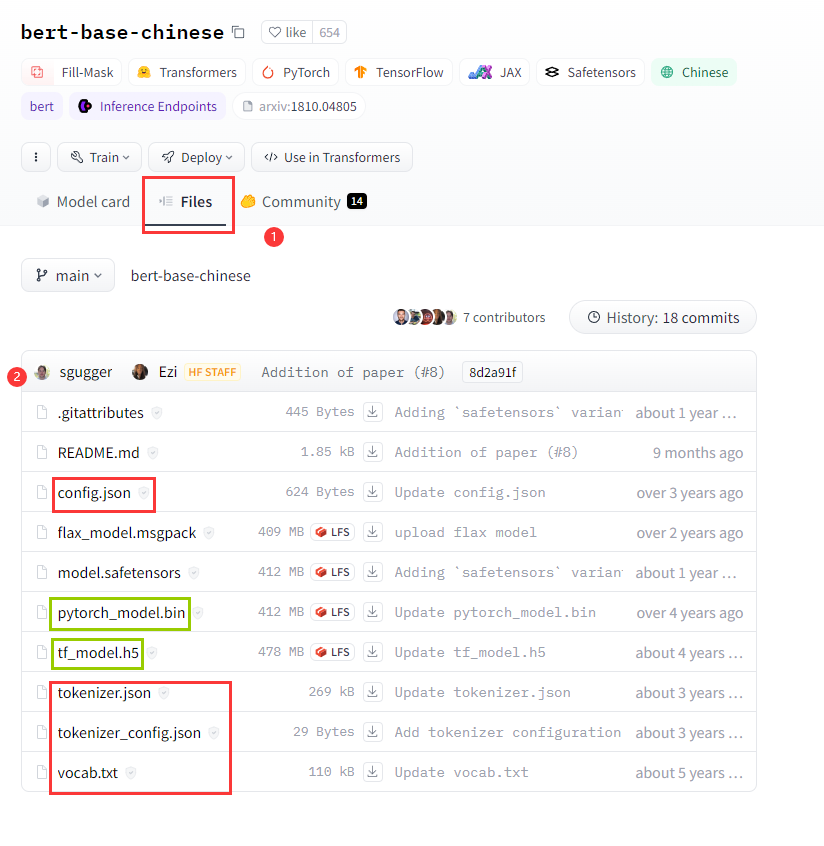
首先我们手动下载中文的bert模型 bert-base-chinese
打开Hugging Face的官网搜索我们想要的模型bert-base-chinese,点击files,下载下面红框内的四个文件,然后根据你使用的框架选择相应的模型文件,如果使用的是pytorch就下载pytorch_model.bin,如果是TensorFlow就换成tf_model.h5,这里我们使用的是pytorch,所以选择pytorch_model.bin进行下载。
将下载好的文件放在我们的项目目录下,比如我这里建立了一个bert-base-chinese文件夹存放:
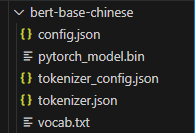
接下来将需要用到该模型的地方修改为我们本地的路径就可以了
修改源代码
spacy默认使用英文分词,我们需要将其改成中文。
将 bert-extractive-summarizer/summarizer/sentence_handler.py 下的代码:
1 | from spacy.lang.en import English |
修改为:
1 | from spacy.lang.zh import Chinese |
测试模型
在主目录下创建test.py测试模型,在这里我们使用的是自己手动下载的模型,使用AutoConfig、AutoTokenizer和AutoModel来加载bert-base-chinese/目录下的模型和相关配置
1 | # coding=utf-8 |
结果:
1 | 准行政院长陈建仁,在公布原文化部长李永得将转任政务委员之后,传出将征询高雄市副市长史哲,出任文化部长。 被称为「点子王」的史哲,不但一手催生驳二和高雄总图,10几年来也不断扩展高雄的设计能量,像是高雄春天艺术节、重办大港开唱等等,史哲都是幕后重要推手,但目前文化部仍有公视法修法和中正纪念堂转型,两大关键政策预计要在今年推动,势必将成为检验内阁改组的重要指标。 立委(国)李德维说:「他过去长期是在民进党内参与政治活动,尤其是相关的学运以及工运,现在却因为担任高雄市的文化局长,就要升任文化部长,真的让人大失所望。」 |
参考文章
 wechat
wechat