『论文笔记』Vulnerability Detection with Graph Simplification and Enhanced Graph Representation Learning
原文标题:Vulnerability Detection with Graph Simplification and Enhanced Graph Representation Learning
原文作者:Xin-Cheng Wen; Yupan Chen; Cuiyun Gao; Cuiyun Gao; Jie M. Zhang
发表期刊:International Conference on Software Engineering (ICSE) 2023
原文链接:https://arxiv.org/pdf/2302.04675
主题类型:源代码漏洞检测,深度学习
笔记作者:isoda
主编:黄诚@安全学术圈
1、研究介绍
图神经网络(GNN)已经被证明了在学习源代码的图表示方面的有效性,并且经常应用于现有的基于深度学习的漏洞检测方法中。然而,GNN仍然受到以下事实限制:
- 因为专注于通过邻域聚合来学习节点的局部特征,GNN 很难处理代码结构图中长距离节点之间的连接依赖,无法捕获图的全局信息。
- 不能很好地利用代码结构图中的多种边类型(如表示数据流和控制流的边)。
为了缓解这一问题,本文提出了一种新的漏洞检测框架AMPLE,主要包括图简化和增强的图表示学习两部分:1)图简化。通过缩小代码结构图的节点大小来减少节点之间的距离,使得GNN更容易处理长距离节点间的依赖关系; 2)增强图表示学习。通过一个边感知图卷积网络模块将异构边信息融合到节点表示中,提高节点表示的准确性。并通过一个核尺度表示模块更好捕获远距离节点之间的关系,提升全局信息的学习效果。实验结果表明,AMPLE在准确性和F1分数方面显著优于现有方法,证明了其在捕捉代码图全局信息和提高漏洞检测效果方面的有效性。
2、主要思路
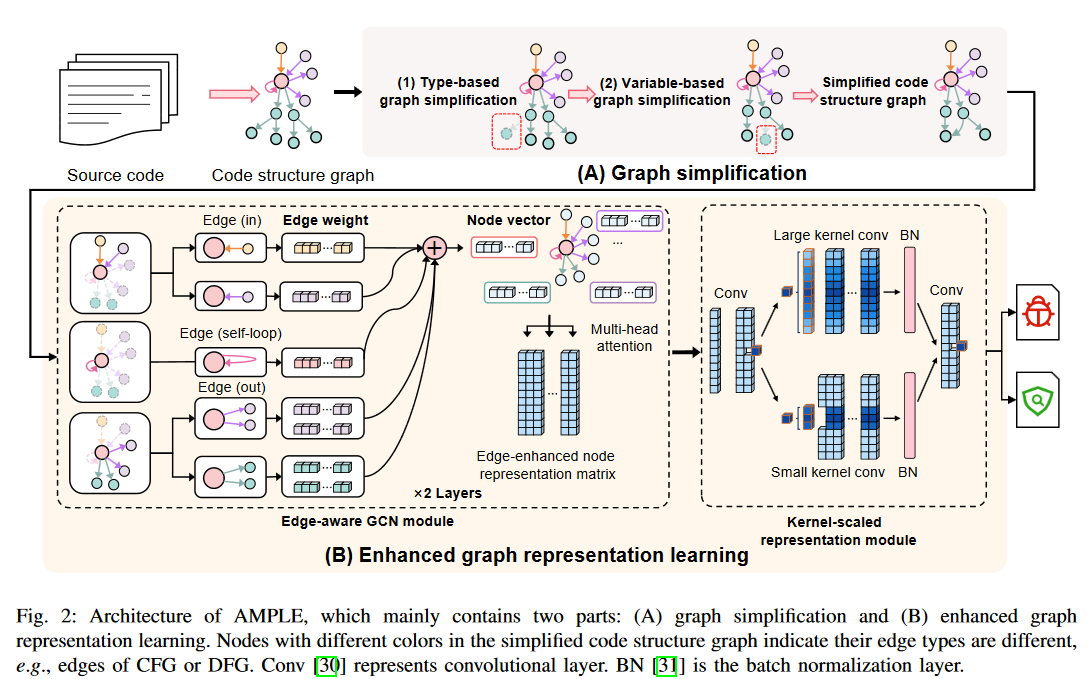
AMPLE整体的流程图如上所示,框架总体来说分为图简化和增强图表示学习两个部分:首先从源代码中提取代码结构图,输入图简化模块,进行基于节点类型和变量类型的图简化;将简化完成后的代码结构图输入增强表示学习模块,通过边感知图卷积网络提取整个图的边增强节点表示矩阵,再通过双尺度卷积核来学习图的全局信息,最后通过两个全连接层和一个softmax函数进行二分类,判断源代码中是否存在漏洞。
2.1、图简化
图简化部分旨在压缩代码结构图中的重复信息,从而缩小图的大小并减少节点之间的距离。该部分主要包括两个步骤:基于节点类型的图简化和基于节点变量的图简化。
-
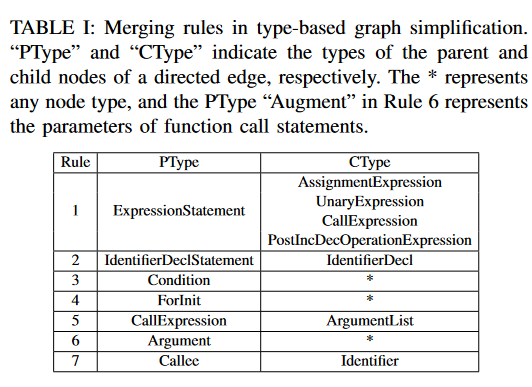
基于节点类型的图简化:通过解析原则和手动检查代码结构图,作者提出了七条合并规则,如表1所示。对于每一对符合合并规则的相邻节点,删除子节点,因为其信息是父节点的细化,并且可以在后续节点中反映。
例如,下图中
char *first = malloc(10)语句是一个标识符声明语句,红色虚线边框的节点就是作为它的子节点可以按照表中的规则2合并到其父节点。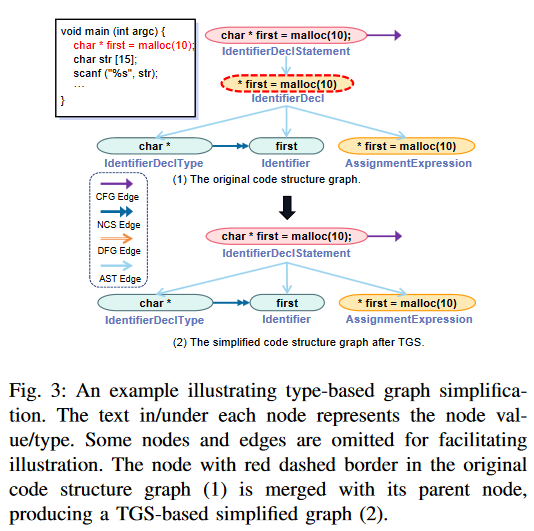
-
基于变量的图简化:将代码结构图中具有相同变量的叶子节点合并为一个节点,使得合并后的节点有多个父节点,可以同时聚合来自不同语句的信息。增强了节点表示的丰富性和准确性的同时并不会改变其父子层次信息。
例如下图中,“char str[15]”和“scanf(”%s”,str);”两个语句的子节点中都存在变量“str”,从而可以合并两个“str”叶节点,“scanf(”%s”,str);”将新的AST边连接合并后的“str”叶节点。

2.2、增强图表示学习
该部分主要包括两个模块:边感知图卷积网络模块和核尺度表示模块。
-
边感知图卷积网络(edge-aware graph convolutional network,EA-GCN)模块:为了利用简化图中的不同边类型(如抽象语法树AST和控制流图CFG)来增强节点表示,作者提出了EA-GCN。
首先对代码结构图中所有节点的嵌入向量进行初始化。将节点中的代码标记为token序列,基于word2vec初始化每个token的嵌入,计算节点中所有token嵌入的平均值,作为整个节点的初始嵌入。
然后在消息传递过程中,分别对不同类型的边加权计算节点向量。进一步引入多头注意力机制整合图中的异构边信息,计算并聚合节点边的注意力分数,以增强节点表示。 最终可以计算得到整个图的边增强节点表示矩阵。
-
核尺度表示模块:核尺度表示模块旨在通过显式捕捉远距离节点之间的关系来学习图的全局信息。
该模块设计了双尺度卷积核,其中大卷积核关注于远距离节点之间的关系,小卷积核关注于邻居节点之间的关系,两个卷积核并行进行卷积操作。两个分支的卷积结果经过批归一化(BN)层处理后相加,将最终的结果通过两个全连接层和一个softmax函数进行二分类,判断源代码中是否存在漏洞。
2.3、实验设置
使用了三个广泛研究的开源C/C++项目基准数据集
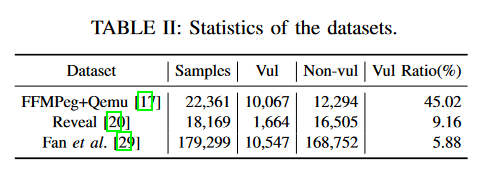
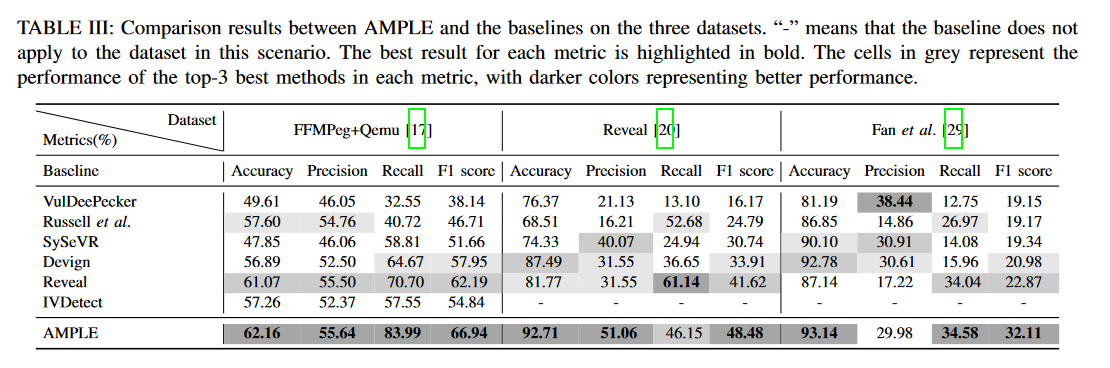
作者将AMPLE与三种基于图和三种基于令牌的SOTA漏洞检测方法分别在选用的所有数据集上进行了比较,可以看到AMPLE基本是全面优于基线模型的。
3、个人思考
- AMPLE围绕基于GNN进行漏洞检测的两大问题展开:1)难以处理代码结构图中长距离节点之间的连接依赖。2)不能很好地利用代码结构图中的多种边类型。作者分别设计了核尺度表示模块和边感知图卷积网络模块来解决这两大问题,模型整体在F1方面相比SOTA模型有显著的提高,论文思路条理十分清晰。
- 尽管图简化方法减少了节点数量,但增强图表示学习模块(EA-GCN和核尺度表示模块)的计算复杂度仍然较高,特别是在处理大型代码库时,可能面临计算资源和时间的挑战。
- 虽然在基准数据集上表现优异,但这些基准数据集均为C/C++数据集,在其他类型编程语言上的泛化能力仍需进一步验证和优化。
- 论文中的方法通过二分类来判断代码片段是否存在漏洞,检测粒度在函数级别和模块/类级别,不能实现漏洞的精确定位。在实际应用中,还需要结合其他技术手段来实现漏洞的精确定位和修复。未来工作可以考虑如何将此方法与精确定位技术结合,提供更全面的漏洞检测和修复方案。
论文团队信息
通讯作者高翠芸,哈尔滨工业大学(深圳)计算机学院终身副教授、博导,学校青年拔尖人才,香港中文大学(CUHK)博士,深圳市“海外高层次人才”,鹏城实验室双聘学者,获得第九届中国科协青年人才托举工程项目。
- 主要研究方向:人工智能+软件工程,大语言模型;漏洞检测
- 70+篇论文发表在程序分析和软件工程领域的顶级会议和期刊上,如TSE、TOSEM、ICSE、 ISSTA、ASE等。
- 个人主页:https://cuiyungao.github.io/
 wechat
wechat